Hive建表语句如下,测试了几个场景
1.单分区,约5亿数据:
2.5分区,约25亿数据
3.10个分区,约50亿数据
CREATE TABLE `test`(
`apply_id` string COMMENT '',
`apply_dt` timestamp COMMENT '',
`partner_nm` string COMMENT '',
`new_or_old` string COMMENT '',
`all_batch_seq_no_td` string COMMENT '',
`first_channel_name` string COMMENT '',
`second_channel_name` string COMMENT '',
`mobile_prov_nm` string COMMENT '',
`mobile_city_nm` string COMMENT '',
`lsjr_cust_lvl` string COMMENT '',
`clec_nm` string COMMENT '',
`star_sign` string COMMENT '',
`gender` string COMMENT '',
`lsjr_cust_id` string COMMENT '',
`succe_lsjr_cust_id` string COMMENT '',
`succe_crdt_lmt` bigint COMMENT '')
COMMENT ''
PARTITIONED BY (
`day_id` timestamp)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
WITH SERDEPROPERTIES (
)
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
'hdfs://xxx'
TBLPROPERTIES (
'orc.compress'='zlib',
'transient_lastDdlTime'='1730444031',
'doris.version'='doris-2.1.6-rc04-653e315ba5',
'doris.file_format'='orc')
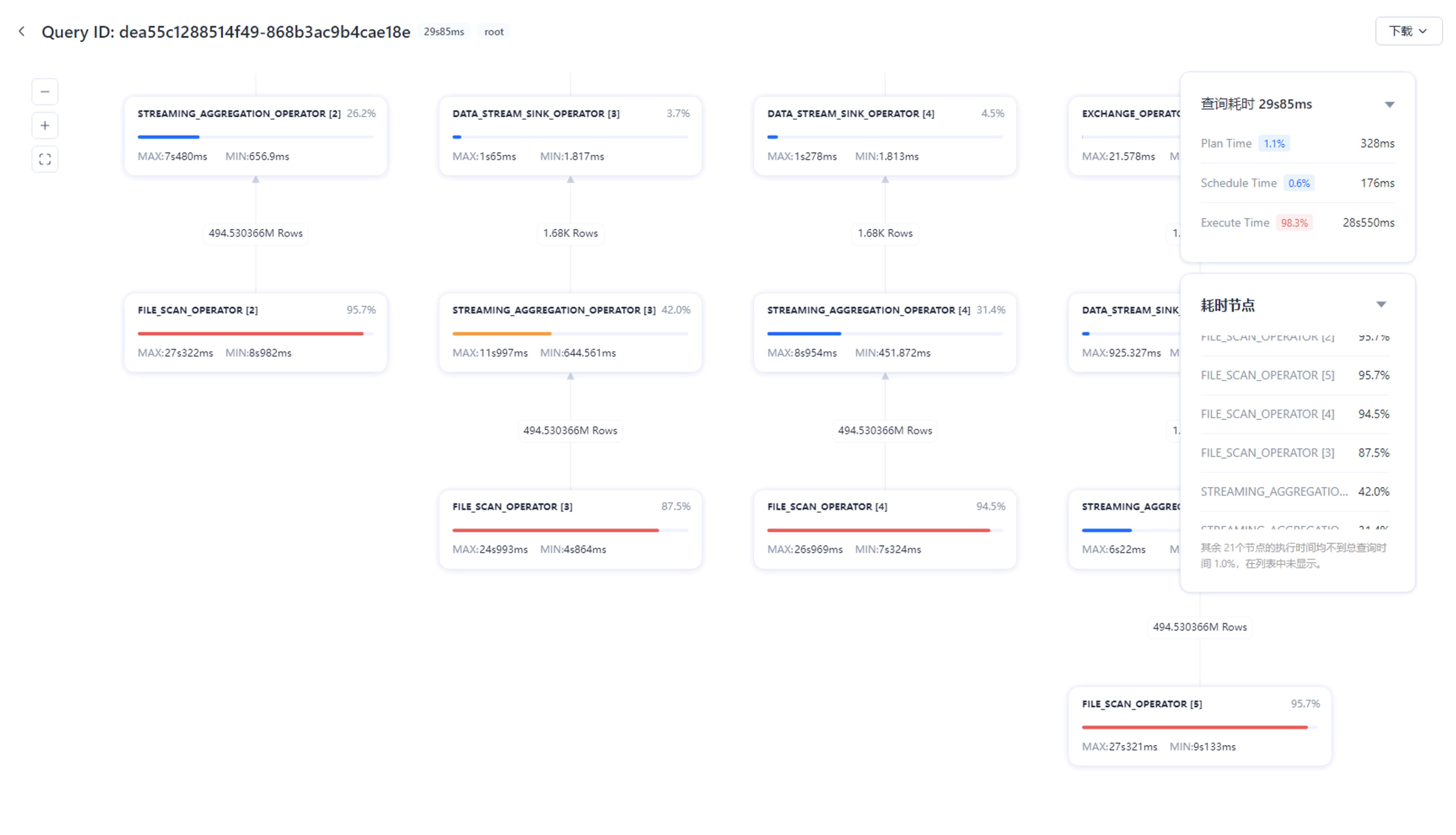
没有开启Data Cache,查看profile,FILE_SCAN_OPERATOR算子消耗时间最长,其次是AGGREGATION_OPERATOR
查询过程中,BE的CPU都会打满,请问下有没有什么查询优化方案吗?