
集群目前有100多G的trash,这其中是有什么关联关系吗。每5秒,20次左右的提交不高啊,一直有一个表总是会出现问题。
有两个配置几乎一样的表,几乎同样的写入频率,但有一个表总是会出现这种修复问题,怎么排查
我的理解可能是这样,应该就是清理垃圾,版本增多,合并压力大,写入提交延迟,判定不健康,副本修复,继续导致写入延迟,一系列连锁反应
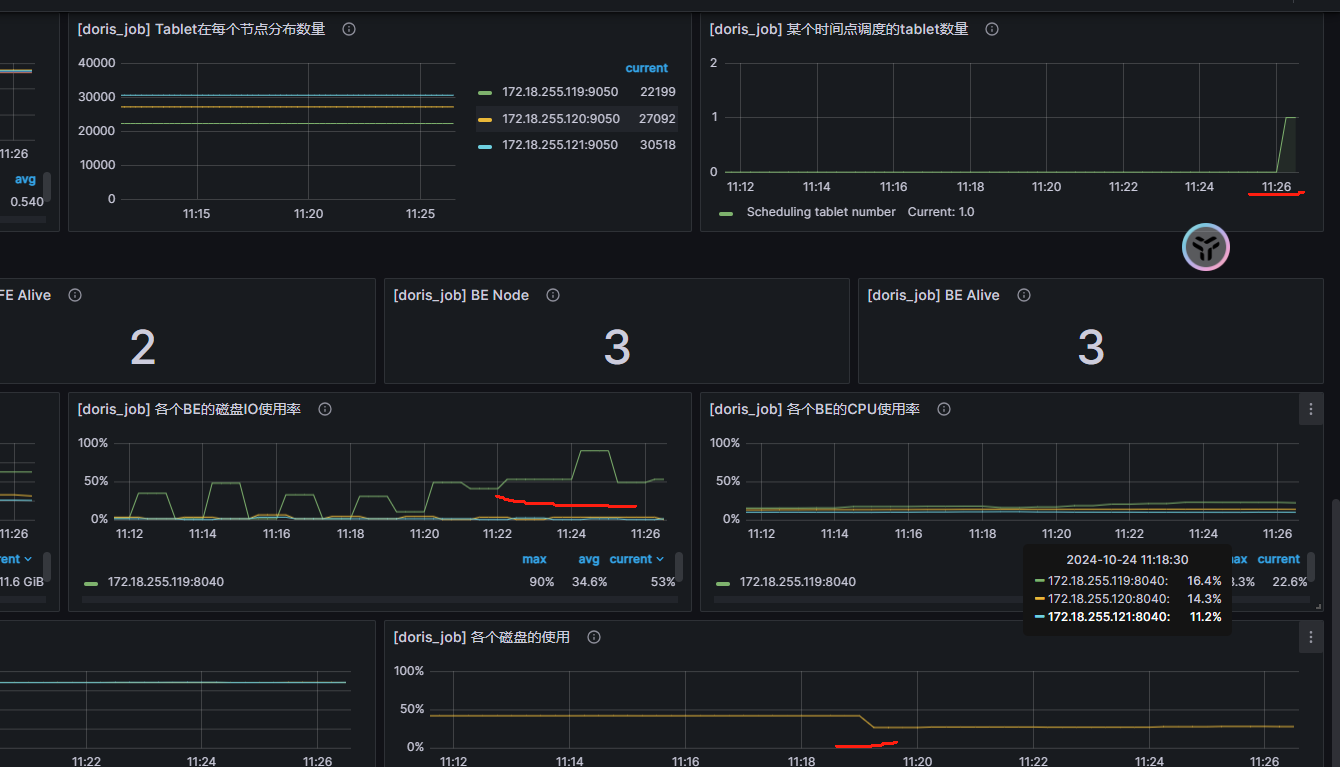
集群目前有100多G的trash,这其中是有什么关联关系吗。每5秒,20次左右的提交不高啊,一直有一个表总是会出现问题。
有两个配置几乎一样的表,几乎同样的写入频率,但有一个表总是会出现这种修复问题,怎么排查
我的理解可能是这样,应该就是清理垃圾,版本增多,合并压力大,写入提交延迟,判定不健康,副本修复,继续导致写入延迟,一系列连锁反应
大量trash 理论上不会影响导入任务,trash只会对磁盘使用率带来影响,可能会导致数据分布不均。
你看下compaction score 这个指标怎么样。同时导入的时候报的错麻烦贴一下详细堆栈。

