环境:doris2.1, 集群部署,4个fe,6个be,测试表30个字段,主键模型 未分区 分桶数12
doris官方文档中jdbc:arrow-flight-sql的效率是mysql jdbc 的几倍
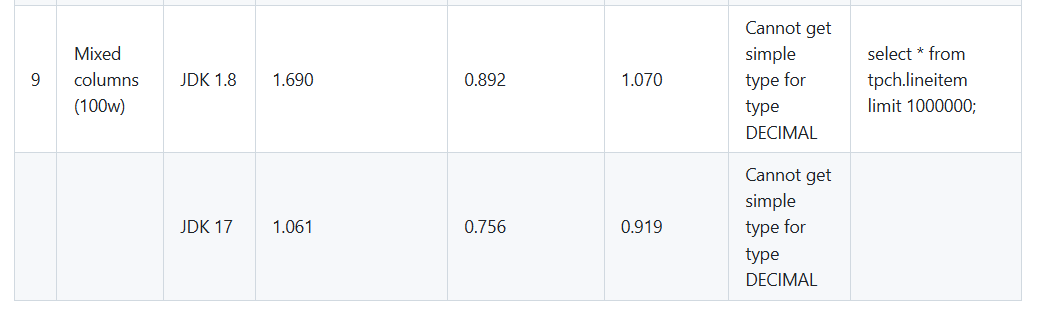
但是实测下来,jdbc:arrow-flight-sql的远远低于mysql jdbc开启流式读取的效率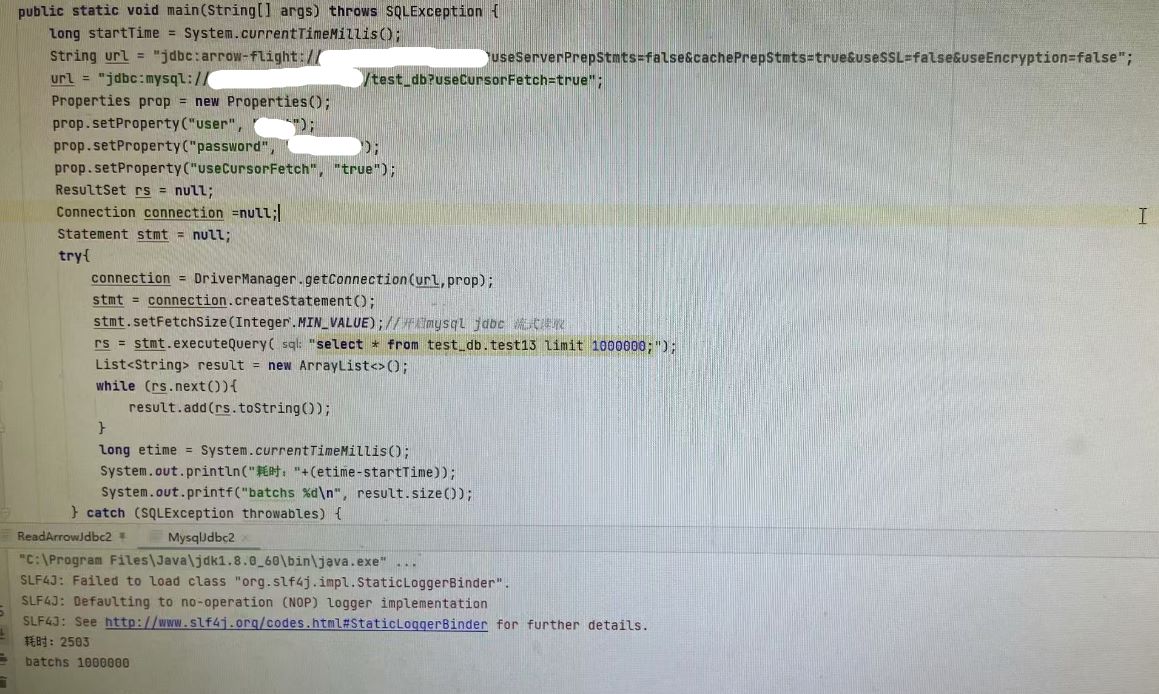

想知道是哪里的优化配置没有开启还是什么其他原因?
jdbc:arrow-flight-sql 读取效率低于mysql jdbc 流式读取的效率
Viewed 78

2 Answers

两个思路,
- 只读一列 int 类型,或只读一列 text 类型试试 性能
- 改用 ADBC client 试试,参考下面的代码
import org.apache.arrow.adbc.core.AdbcConnection;
import org.apache.arrow.adbc.core.AdbcDatabase;
import org.apache.arrow.adbc.core.AdbcDriver;
import org.apache.arrow.adbc.core.AdbcStatement;
import org.apache.arrow.adbc.core.AdbcStatement.QueryResult;
import org.apache.arrow.adbc.driver.flightsql.FlightSqlDriver;
import org.apache.arrow.flight.Location;
import org.apache.arrow.memory.BufferAllocator;
import org.apache.arrow.memory.RootAllocator;
import org.apache.arrow.vector.VectorSchemaRoot;
import org.apache.arrow.vector.ipc.ArrowReader;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class FlightSqlAdbcDemoOnlyLoad {
public static void main(String[] args) throws Exception {
final BufferAllocator allocator = new RootAllocator();
FlightSqlDriver driver = new FlightSqlDriver(allocator);
Map<String, Object> parameters = new HashMap<>();
AdbcDriver.PARAM_URI.set(parameters, Location.forGrpcInsecure("127.0.0.1", 8029).getUri().toString());
AdbcDriver.PARAM_USERNAME.set(parameters, "root");
AdbcDriver.PARAM_PASSWORD.set(parameters, "");
AdbcDatabase adbcDatabase = driver.open(parameters);
AdbcConnection connection = adbcDatabase.connect();
AdbcStatement stmt = connection.createStatement();
long stime = System.currentTimeMillis();
stmt.setSqlQuery(args[0]);
// executeQuery, two steps:
// 1. Execute Query and get returned FlightInfo;
// 2. Create FlightInfoReader to sequentially traverse each Endpoint;
QueryResult queryResult = stmt.executeQuery();
ArrowReader reader = queryResult.getReader();
List<String> result = new ArrayList<>();
while (reader.loadNextBatch()) {
VectorSchemaRoot root = reader.getVectorSchemaRoot();
// String tsvString = root.contentToTSVString();
// result.add(tsvString);
}
long etime = System.currentTimeMillis();
System.out.printf("cost:%d ms.\n", (etime - stime));
System.out.printf("batchs %d\n", result.size());
reader.close();
queryResult.close();
stmt.close();
connection.close();
}
}
