先把表列出来,然后说明情况。
-- data_platform_dw.ddp_user_flow_source definition
CREATE TABLE `ddp_user_flow_source` (
`event_time` DATETIME(3) NOT NULL COMMENT '事件时间',
`os_code` VARCHAR(65533) NOT NULL COMMENT '数据来源系统',
`message` JSON NOT NULL COMMENT '消息,用json存储,不同的系统有不同的数据结构'
) ENGINE=OLAP
DUPLICATE KEY(`event_time`, `os_code`)
COMMENT '用户流量监控源表'
PARTITION BY RANGE(`event_time`)()
DISTRIBUTED BY HASH(`event_time`, `os_code`) BUCKETS AUTO
PROPERTIES (
"replication_allocation" = "tag.location.default: 2",
"min_load_replica_num" = "-1",
"is_being_synced" = "false",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-365",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.replication_allocation" = "tag.location.default: 2",
"dynamic_partition.buckets" = "10",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.history_partition_num" = "-1",
"dynamic_partition.hot_partition_num" = "0",
"dynamic_partition.reserved_history_periods" = "NULL",
"dynamic_partition.storage_policy" = "",
"storage_medium" = "hdd",
"storage_format" = "V2",
"inverted_index_storage_format" = "V1",
"light_schema_change" = "true",
"disable_auto_compaction" = "false",
"enable_single_replica_compaction" = "false",
"group_commit_interval_ms" = "10000",
"group_commit_data_bytes" = "134217728"
);
insert into ods_oss_file_operate_detail
select
json_extract_string(message,'$.appId') as app_id,
json_extract_string(message,'$.fileName') as file_name,
json_extract_string(message,'$.uid') as uid,
json_extract_string(message,'$.geTime') as ge_time,
json_extract_string(message,'$.storageSource') as storage_source,
json_extract_string(message,'$.interfaceCode') as interface_code,
json_extract_bigint(message,'$.execTime') as exec_time,
json_extract_string(message,'$.size') as `size`,
json_extract_string(message,'$.bucket') as bucket,
json_extract_string(message,'$.oldBucket') as old_bucket,
json_extract_string(message,'$.oldFileName') as old_file_name,
json_extract_string(message,'$.clientIp') as client_ip,
json_extract_string(message,'$.operateUserCode') as operate_user_code,
json_extract_string(message,'$.storagePath') as storage_path,
json_extract_string(message,'$.fileExpirationTime') as file_expiration_time,
json_extract_string(message,'$.storageDuration') as storage_duration,
json_extract_string(message,'$.dataExpirationTime') as data_expiration_time
from
ddp_user_flow_source
where
event_time > ${preTime}
and
os_code = 'oxms-operate'
and
json_extract_string(message,'$.uid') is not null
and
json_extract_string(message,'$.appId') is not null;
该表要接收各个业务线的数据, 然后用json_extract_xxx解析json将数据分发到各个业务的的原始明细表中。 该表一天10亿的数据导入(通过routine load)。 然后各个业务线会定时微批抽这个表的数据。 也就是说,这个表的读写负载是很大的。这是背景。
现在通过dolphinscheduler调度,每天都会有调度失败的任务(好多次)。如下: 有些甚至超时时间还不足1秒就报错了。

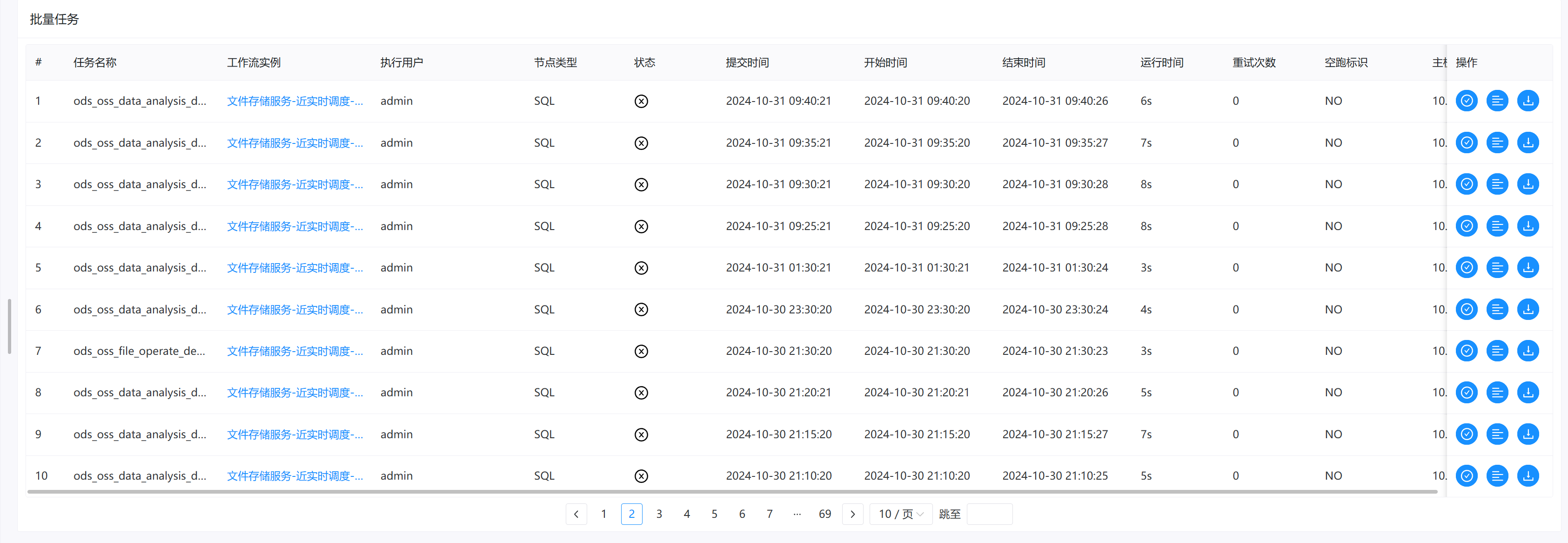
对应的时间点, 资源是充足的:
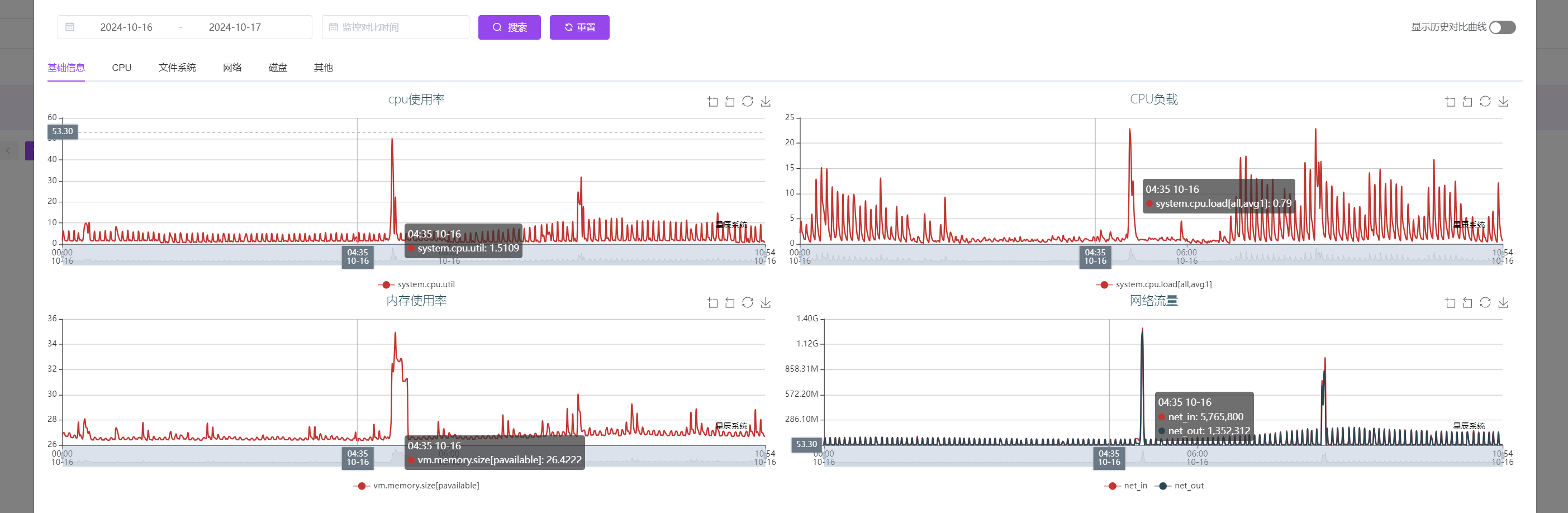
除了晚上的调度任务,其他时间段的曲线是很低的。
关于服务器:
这套服务器的配置不低。 64C 512G 44T(机械)
结论:
我合理怀疑是某个参数限制了资源使用, 资源超过了参数限制,直接拒了连接,所有就报错了。
就像 parallel_fragment_exec_instance_num这个参数默认较低没有充分利用集群资源一样。
该问题是当前生产问题,希望得到解决。 我觉得增加超时时间,并没有解决根因。

