使用的doris版本是 2.0.4 ,以下是具体复现步骤,求大神关注:
1.新建一张hive中 orc格式的分区表,以int类型的dt作为为分区,如下
CREATE TABLE IF NOT EXISTS dbname.table_name (
id bigint,
type bigint ,
state string
) COMMENT ‘’
PARTITIONED BY (dt INT COMMENT ‘yyyymmdd’)
STORED AS ORC
tblproperties (‘orc.compress’ = ‘SNAPPY’);
2.使用spark sql通过INSERT OVERWRITE TABLE dbname.table_name PARTITION(dt=xxxx) 写入多个分区的数据,如 dt=20240228,dt=20240227,dt=20240226,dt=20240225
3.新增字段,执行如下ddl
ALTER TABLE dbname.table_name ADD COLUMNS(
sensitive_query_flag BIGINT COMMENT ‘’
)cascade;
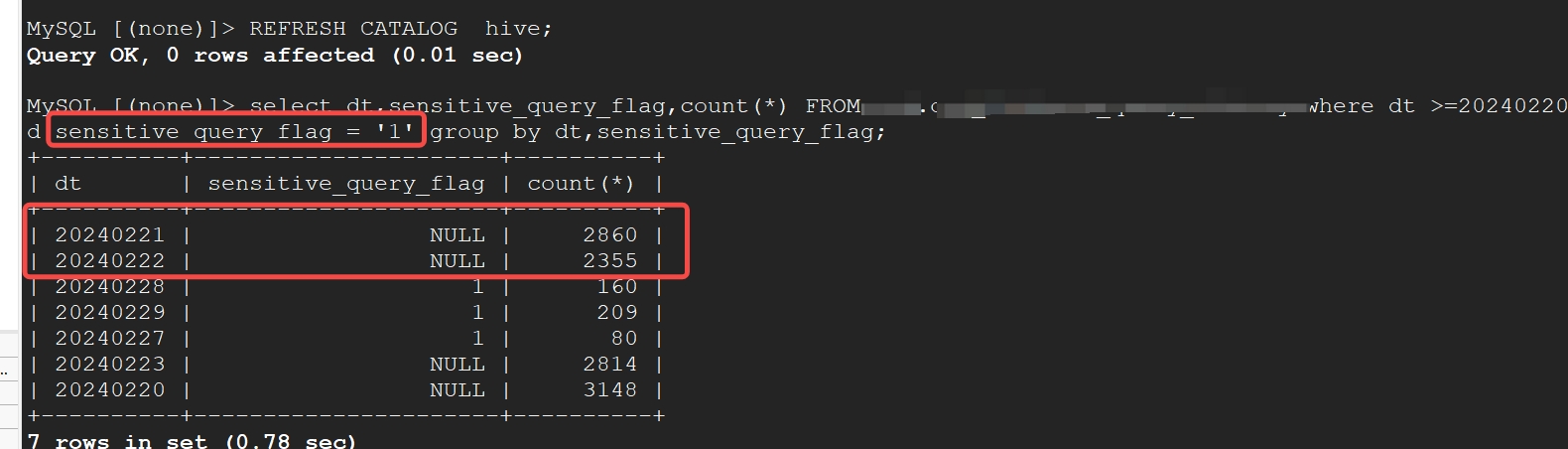
4.再次通过 INSERT OVERWRITE TABLE dbname.table_name PARTITION(dt=20240228) 刷入20240228分区的数据,在我的使用场景中sensitive_query_flag 值为0或1,此时通过sensitive_query_flag = 1 对 dt>=20240225 进行过滤时,只会对重新写入的分区 dt=20240228生效,对其余分区的结果均表现为失效,查出的结果包括值为NULL的情况
按照以上结果执行结果图如下(以新增字段作为where条件,只会对添加字段后重新写入的分区生效,对历史分区会存在错误数据):