背景
在实际线上生产环境中,大家可能遇到过BE 宕机的问题,Apache Doris 的BE部分是由C++编写,当出现一些内存越界,非法访问的问题时会导致BE进程的Crash,同时也比较难排查,我们通过几个例子来带大家一起分析下。同时一般为了减小此类问题对线上业务造成影响,大家都会通过一些特殊方案来避免,比如:
- 容灾备份、读写分离、建设两地三中心等: 跨集群数据同步
- 手动配置 Service 自动拉起:服务自动拉起 - Apache Doris。服务自动拉起
- Manager 接管集群进行服务自动拉起:Doris Manager
BE宕机的情况分类:
目前一般遇到的有这么几种情况:
- BE 进程非正常退出
a. 有 bug 导致BE进程Crash
b. BE 进程OOM - BE 进程正常退出
这里我们主要看非正常退出这块。因为其实有部分情况是这样的,有些同学和运维同学内部没有对齐,可能服务器reboot了或者什么情况,所以一般出现问题后,可以先和相关的同学对齐下,看看是否有其他操作。
如何判断是 BE 进程是 Crash还是OOM了。
- 首先可以看be/log/be.out中是否有堆栈信息,如果有堆栈信息输出就是crash了,如下:
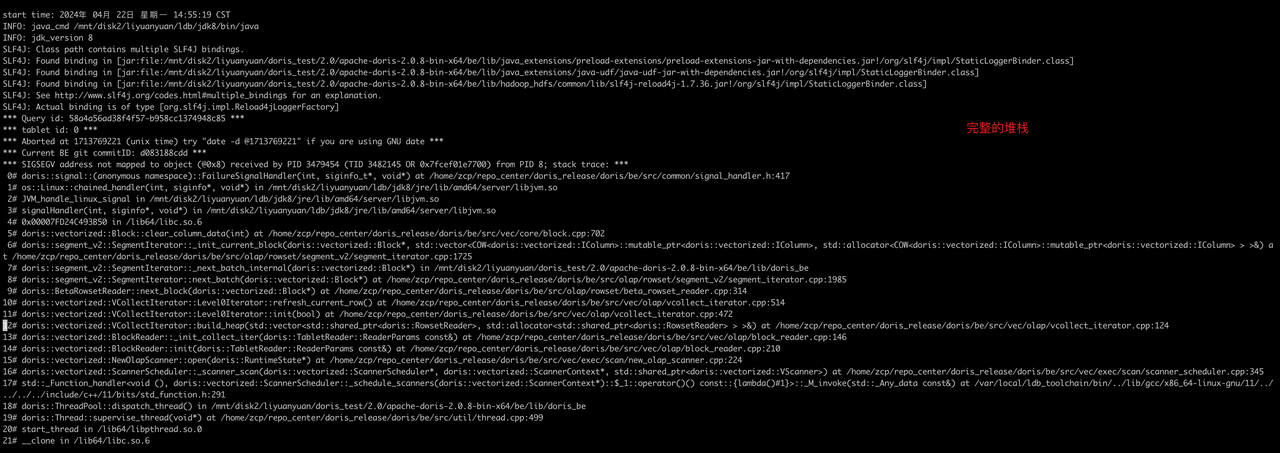
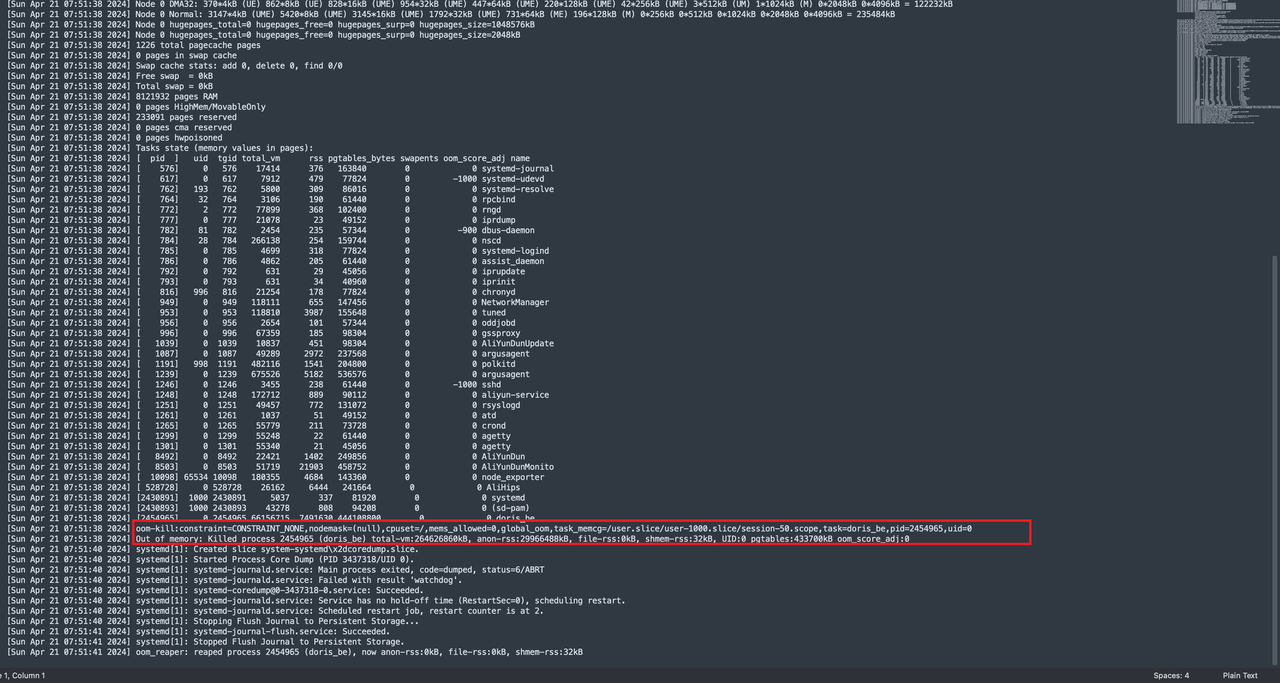
- 如果没有堆栈信息,只有一些启动信息的话,可以通过执行dmesg -T 看看是否是OOM,如果是OOM会有Killed的日志
BE Crash 后如何排查:
- 首先BE core了之后先不要着急,可以先尝试将服务拉起来(建议配置自动拉起),后续继续排查。首先观察堆栈信息,堆栈中有一个 Query id ,这个一般是导致BE core的query
- 通过 query_id 定位下是哪条sql导致的,需要去fe下fe.audit.log中grep下,注意要去所有FE 节点进行搜索,因为如果是做了负载均衡的话可能是发送到其中一个fe节点执行的,因为查询这种不涉及元数据操作的sql是不会转发到master的。比如:grep "58a4a56ad38f4f57-b958cc1374948c85" fe/log/fe.audit.log
- 定位出是哪条sql导致的,可以先把这条sql禁止掉,同时方便的话可以整理下涉及到的表的schema信息等,把be.out + 整理的信息提供给社区同学,方便复现和定位问题。
- 等待社区同学进行分析和判断,同时可以判断下这个问题的影响面。
a. 如果这个问题比较严重,且是未知问题,可以先等社区分析和修复,着急的话可以联系社区同学提供patch包(patch包没有经过回归测试,所以需要评估)。
b. 如果是已知问题,并且在新版本已经修复,那么可以考虑通过升级解决这个问题。
特殊情况:
有时候问题比较难复现,排查问题的周期也会比较长,如果问题比较严重,那么对用户业务的影响面还是比较大的,所以有时需要用户环境生成的 core 文件来配合进行debug,来尽快的定位和fix问题。下边介绍下如何取core文件。
-
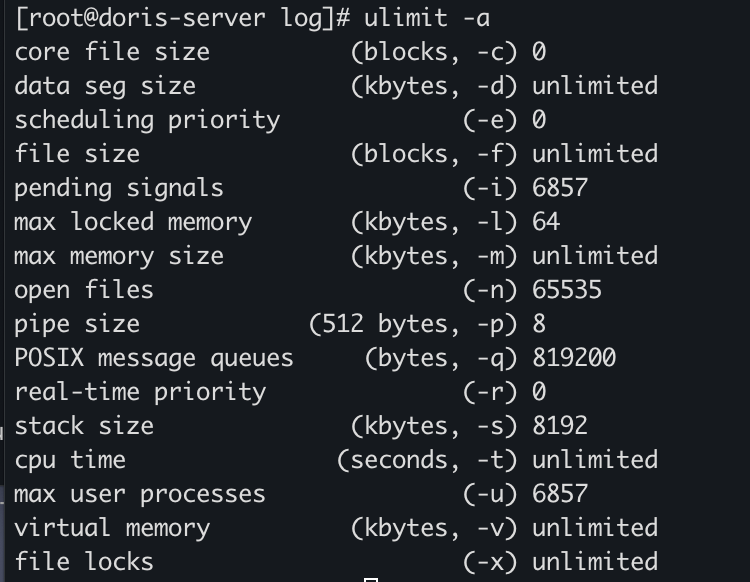
查看生成CoreDump文件的开关是否开启,输入命令 ulimit -a
-
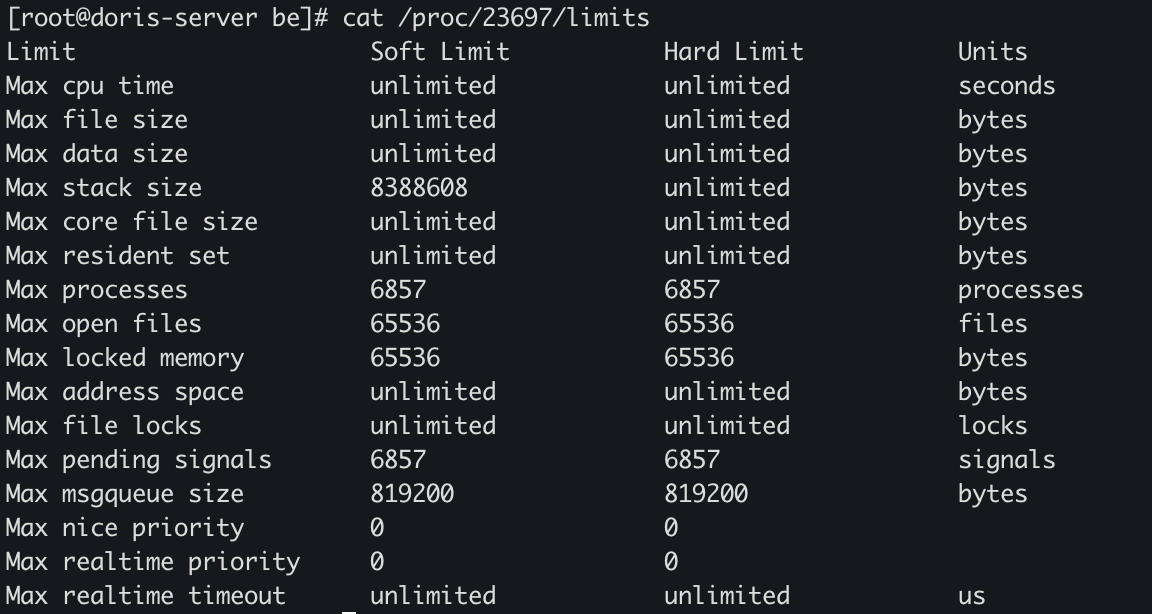
第一行 core file size 为0,则不会生成CoreDump。使用 ulimit -c [kbytes] 命令可以设置系统允许生成的CoreDump的文件大小。所以在BE启动时,加入以下命令 即可ulimit -c unlimited -n 65536 && sh start_be.sh --daemon启动后可以通过 cat /proc/{be pid}/limits 确认是否成功开启coredump,core file size是 unlimited 则表示已经成功打开。
-
此时,就会在BE Crash的时候,生成CoreDump文件,默认的位置是在BE目录下,如果BE目录下没有core文件吗,执行以下命令,这里显示CoreDump文件被core_pattern定义设置在了/tmp目录下,所以需要到对应的目录查找BE生成的CoreDump文件。
cat /proc/sys/kernel/core_pattern/tmp/core_%t_%e_%p
-
方便的话可以把core文件进行压缩上传到对象存储上,然后提供给社区同学进行问题的定位和fix
BE OOM 后如何分析:
一般大家在使用的过程中会遇到内存泄漏不释放,或者是因为一些大query和load任务导致OOM的情况,下文带大家一起实操一把,如何进行分析。首先可以参考官网OOM的分析以及memtracker如何看:
BE OOM分析 - Apache Doris
内存跟踪器 - Apache Doris
Cache 没及时释放导致BE OOM(2.0.3-rc04):
-
BE 出现宕机,且已经通过dmesg -T 确定是OOM

-
这时候如果有部署监控,可以通过监控看下具体内存的使用情况

-
通过BE重启的时间节点,找到最后一次打印的memtracker的统计信息进行分析

-
从这个日志中可以详细的看到各个模块在内存的使用情况
BE 进程总共使用了209.01 GB
内存中 导入69G,其中 LoadChannelMgr 33G
page cache 46G
jemalloc cache 15G
brpc IOBufBlockMemory 5G
SegCompaction 13G
orphan 77G
其中应该大部分是 segment cache、tablet schema 等元数据内存
分析: minor gc 只会淘汰过期的cache,full gc才会淘汰所有cache,因为 GC 线程卡住,一直没到full gc,所以page cache等一直没释放,最终导致OOM。
临时规避方式:
- 调低 jemalloc purge dirty page 时间,be.conf 中修改 JEMALLOC_CONF,把 dirty_decay_ms:15000 改成 dirty_decay_ms:3000, 预期对性能的影响很小。
- be.conf 中增加 soft_mem_limit_frac=1,mem_limit=75%,确保只会触发full gc补充,目前2.0最新的tag,已经将 jemalloc purge dirty page改成异步的了,不会再阻塞gc过程
大查询导致BE OOM:
-
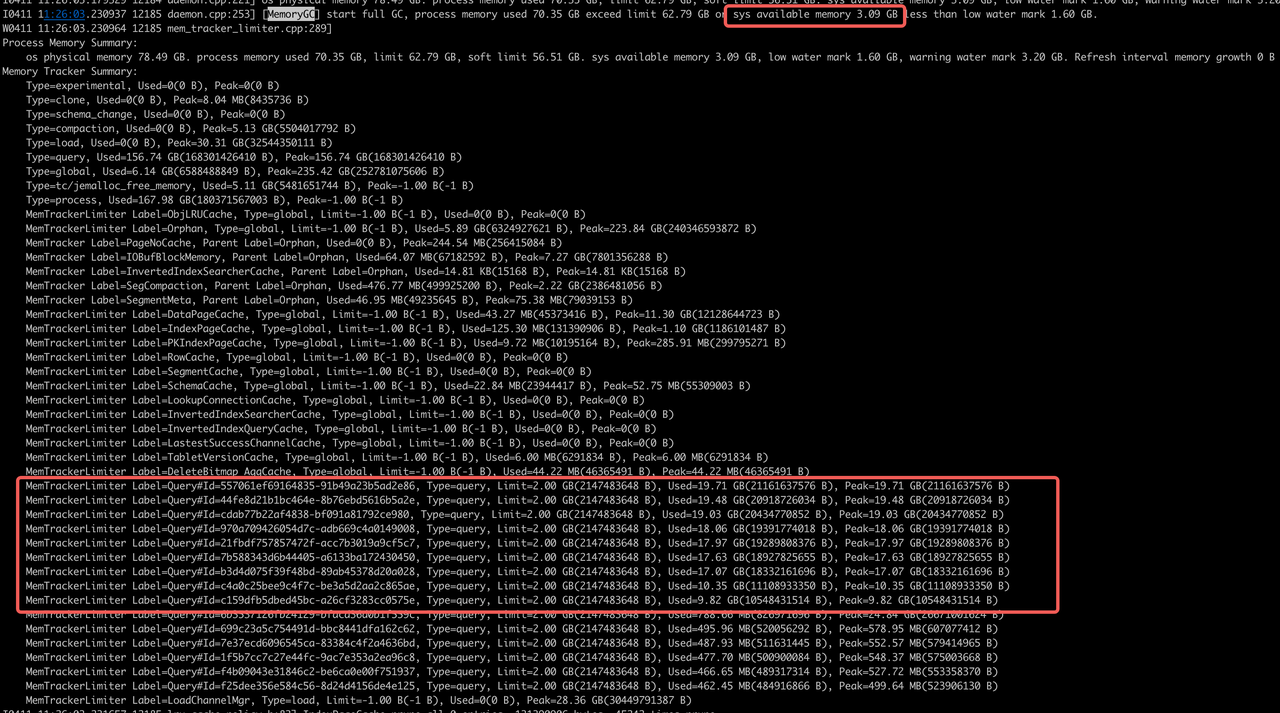
通过BE重启的时间节点,找到最后一次打印的memtracker的统计信息进行分析
-
从这里memtracker统计信息中能看到query占了156.74 GB
没cancel完成的query分析
OOM时间点:11:26:04.00
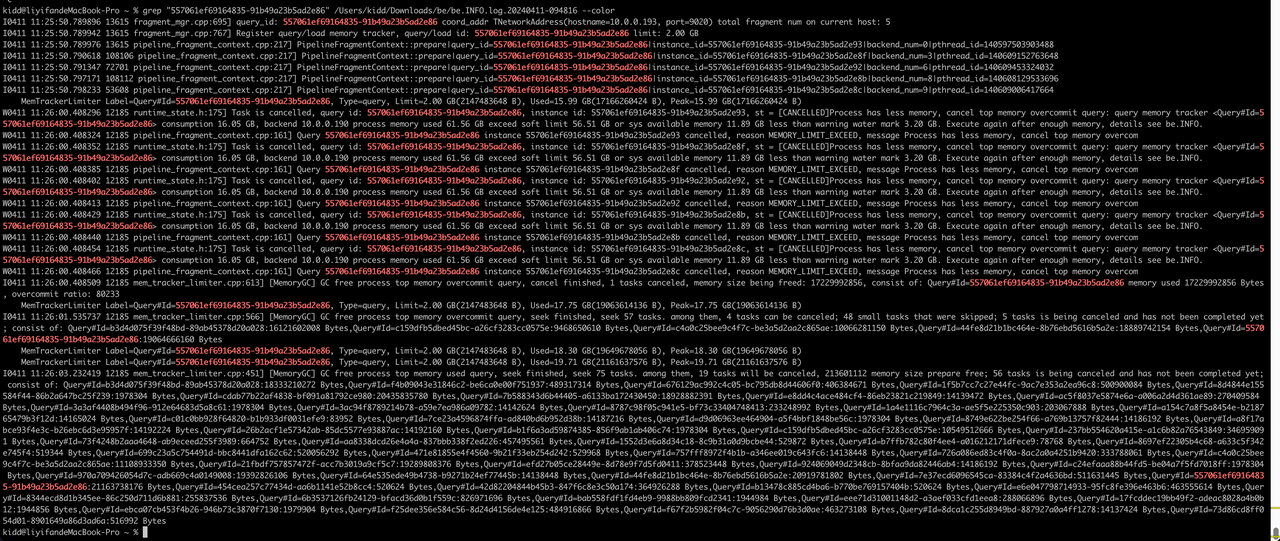
a. 557061ef69164835-91b49a23b5ad2e86,11:25:50.78提交,11:26:00系统内存不足被cancel,
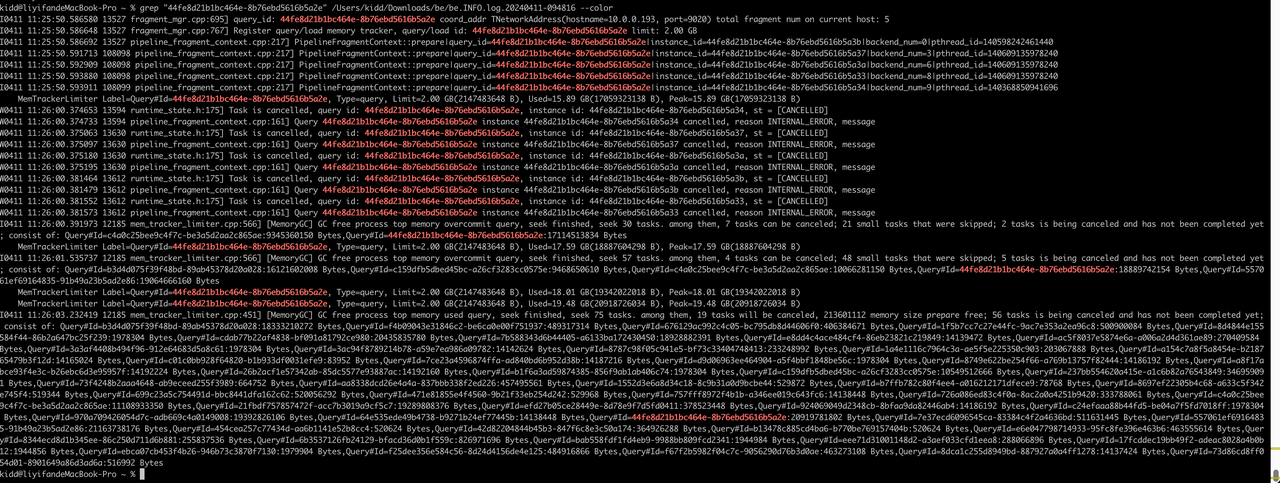
b. 44fe8d21b1bc464e-8b76ebd5616b5a2e, 11:25:50.58提交,11:26:01.53系统内存不足被cancel
c. 21fbdf757857472f-acc7b3019a9cf5c7,11:25:50.62 提交,11:26:02.12系统内存不足被cancel
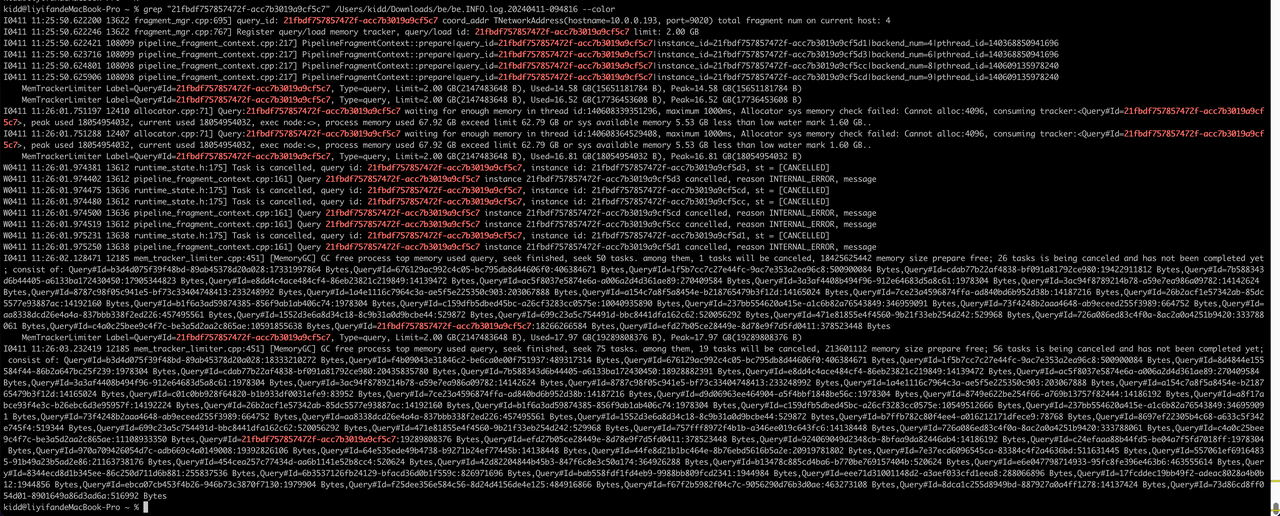
MemTrackerLimiter Label=Query#Id=557061ef69164835-91b49a23b5ad2e86, Type=query, Limit=2.00 GB(2147483648 B), Used=19.71 GB(21161637576 B), Peak=19.71 GB(21161637576 B)
MemTrackerLimiter Label=Query#Id=44fe8d21b1bc464e-8b76ebd5616b5a2e, Type=query, Limit=2.00 GB(2147483648 B), Used=19.48 GB(20918726034 B), Peak=19.48 GB(20918726034 B)
MemTrackerLimiter Label=Query#Id=cdab77b22af4838-bf091a81792ce980, Type=query, Limit=2.00 GB(2147483648 B), Used=19.03 GB(20434770852 B), Peak=19.03 GB(20434770852 B)
MemTrackerLimiter Label=Query#Id=970a709426054d7c-adb669c4a0149008, Type=query, Limit=2.00 GB(2147483648 B), Used=18.06 GB(19391774018 B), Peak=18.06 GB(19391774018 B)
MemTrackerLimiter Label=Query#Id=21fbdf757857472f-acc7b3019a9cf5c7, Type=query, Limit=2.00 GB(2147483648 B), Used=17.97 GB(19289808376 B), Peak=17.97 GB(19289808376 B)
MemTrackerLimiter Label=Query#Id=7b588343d6b44405-a6133ba172430450, Type=query, Limit=2.00 GB(2147483648 B), Used=17.63 GB(18927825655 B), Peak=17.63 GB(18927825655 B)
MemTrackerLimiter Label=Query#Id=b3d4d075f39f48bd-89ab45378d20a028, Type=query, Limit=2.00 GB(2147483648 B), Used=17.07 GB(18332161696 B), Peak=17.07 GB(18332161696 B)
结论:query cancel不及时导致OOM,情况比较极端:
a. 11:25:50 同一时间提交了10个左右大查询,每个内存都在10G+
b. 11:26:00 - 11:26:02 GC发现系统内存不足陆续cancel了这10个query,此时系统可用内存只剩3G
c. 11:26:04 BE进程OOM,query没有cancel完成
目前2.1 版本上目前修复了一些 query cancel 慢的问题
规避方式:
be.conf 中增加
max_sys_mem_available_low_water_mark_bytes=6871947672 (默认1.6G,改成6.4G或3.2G)
总结
在Doris的使用过程中,由于大家的环境和使用场景都不同,压力大小也不同,所以可能都会遇到一些问题。目前Doris也在不断的补充case进行全面覆盖,用来提高Doris的稳定性。好的产品一定是大家共同打磨出来的。遇到问题可以在 ask 论坛(https://ask.selectdb.com/)上进行提问,会有专门负责的同学来处理问题,也可以直接在社区群里进行提问,会有专门的同学进行问题的跟进和处理。
