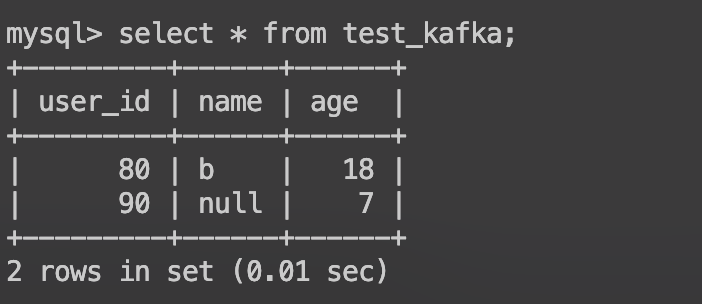
------测试导入的表
CREATE TABLE test_kafka(
user_id BIGINT NOT NULL COMMENT "用户 ID",
name VARCHAR(20) NOT NULL COMMENT "用户姓名",
age INT COMMENT "用户年龄"
)
unique KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 1;
------添加测试数据
vi streamload_example.csv
80,b,18
90,null,a
aa,a,12
-----执行数据导入
curl --location-trusted -u root:
-H "Expect:100-continue"
-H "max_filter_ratio:0.4"
-H "merge_type: append"
-H "column_separator:,"
-H "columns:user_id,name,age"
-H "timeout:3000"
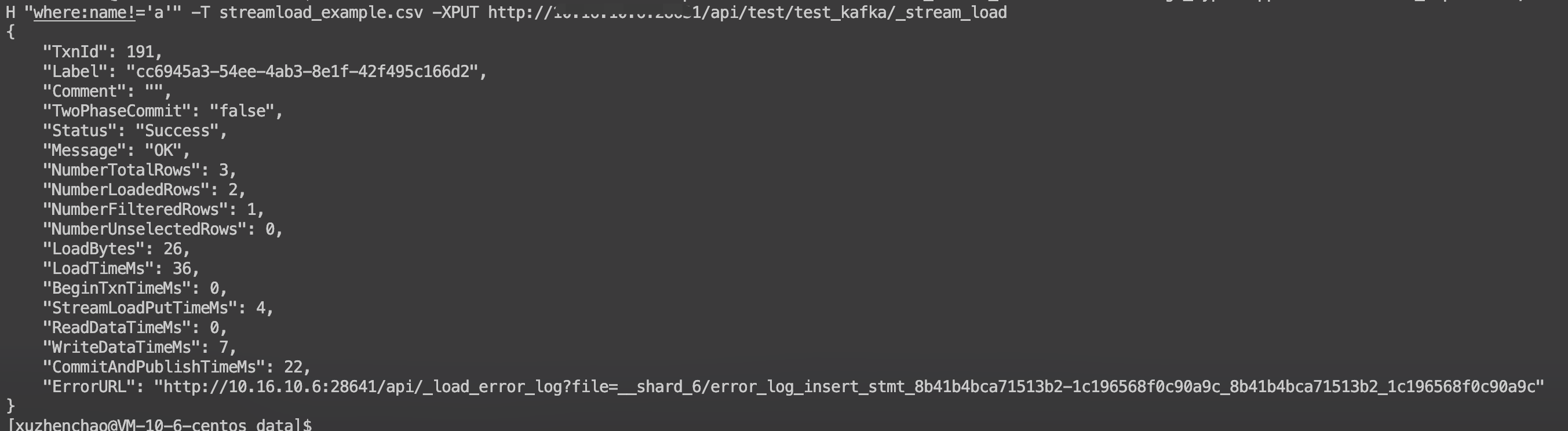
-H "where:name!='a'"
-T streamload_example.csv
-XPUT http://192.168.0.000:8030/api/awhtest/test_kafka/_stream_load
导入报错提示:Reason: column(user_id) values is null while columns is not nullable. src line [aa a 12];
我的疑问是:-H "where:name!='a'" 这条数据通过where条件设置不能过滤掉吗?