Doris版本:2.1.3
服务器配置:16核32G
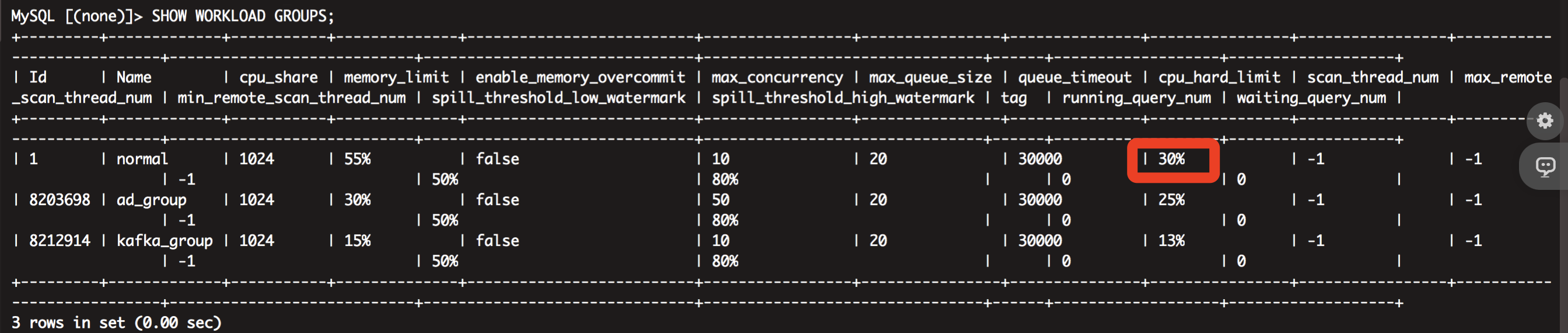
现象:cpu_hard_limit硬限制没起作用,超过了workload group组设置的CPU上限
具体场景描述:
wangxing用户所属workload group组是normal,且设置了cpu_resource_limit线程数
SET PROPERTY FOR 'wangxing' 'cpu_resource_limit' = '30';
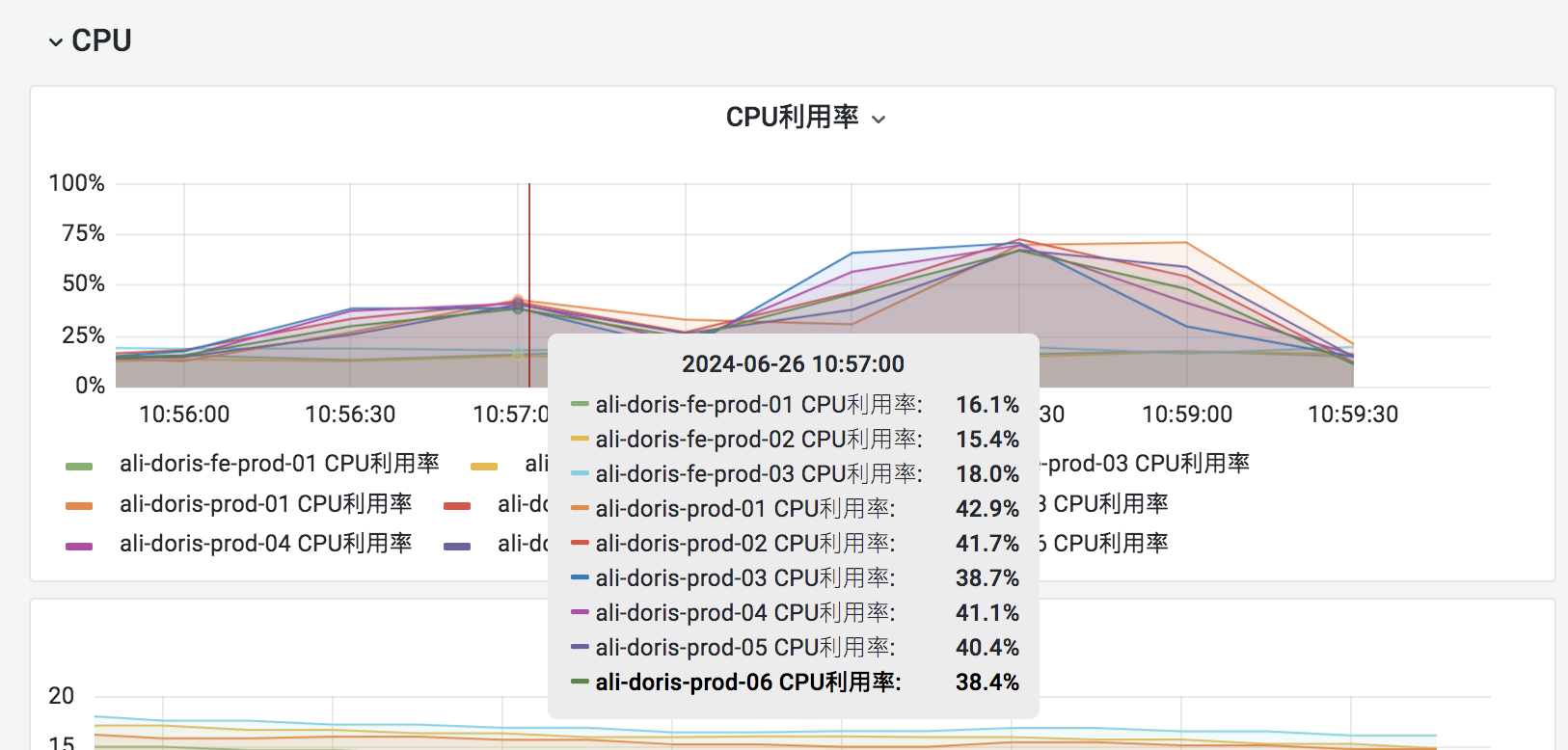
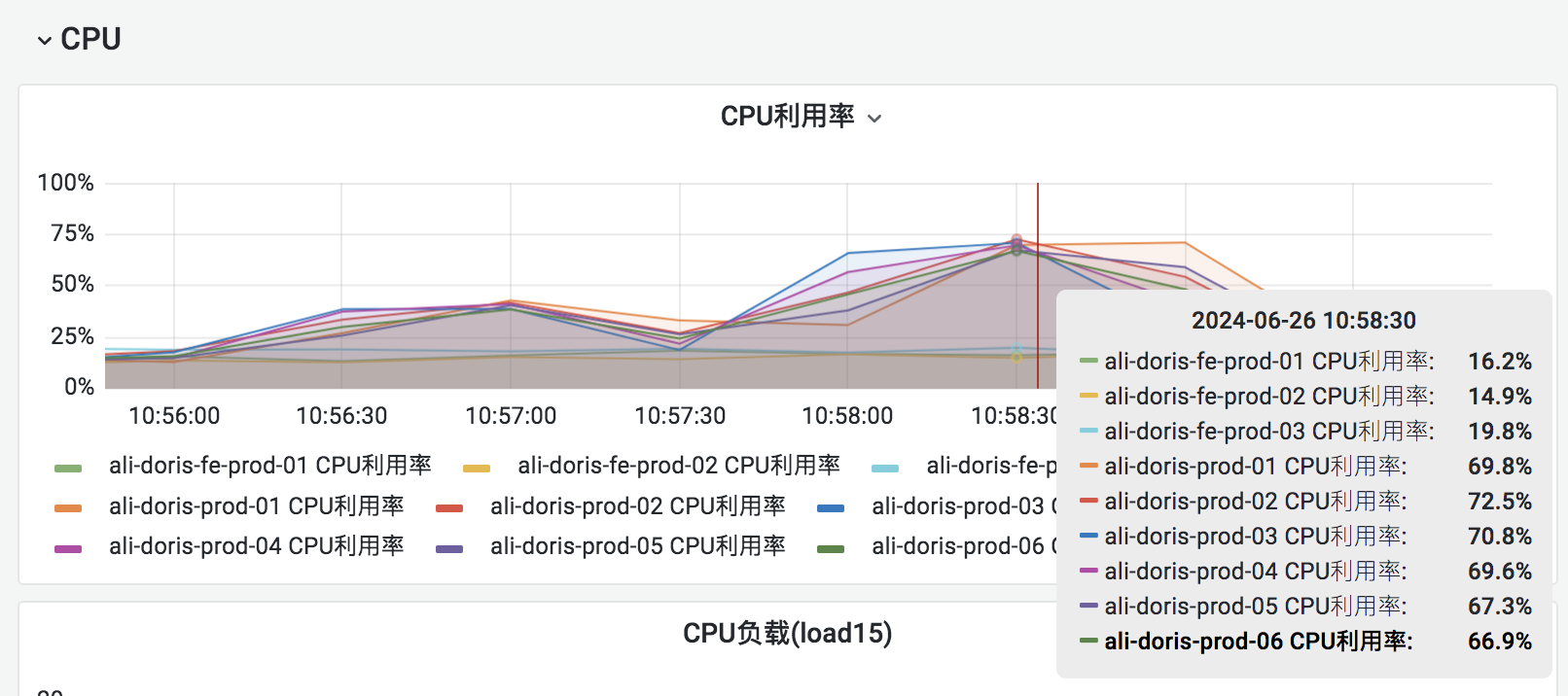
然后发现当用wangxing用户一个查询时cpu在40%左右,当同时执行两个大查询SQL后CPU能用到70%左右,用户所属workload group组是normal,
问题:
1、这是cpu_hard_limit硬限制没起作用?还是cpu_resource_limit线程数和cpu_hard_limit不能共用?
2、还是说workload group限制的也是单个SQL查询?
cpu_hard_limit硬限制没起作用
Viewed 111
3 Answers
调高用户的cpu_resource_limit这个参数后,CPU使用率升高现象就会很明显,远超于workload资源限制
设置cpu_resource_limit之后,scan逻辑走的是独立的线程池,不受workload group的管理。
这个是旧版本间接限制cpu使用的逻辑,主分支目前没有删除是考虑有历史用户在用。
所以设置workload group的话,就别配置这个参数了,如果按照workload group文档页面的操作还是限不住,那可能是有些问题,比如是compaction,导入的部分逻辑以及其他后台线程占cpu较高。
验证方法就是你可以top命令分析下具体的cpu使用在各个线程的分布,预期group的线程没超,但是LimitedScanThreadPool这个线程会占的比较多,如果配置了cpu_resource_limit

你这里设置的cpu_hard_limit步骤是什么样的?看样子没有生效。可以参考下下面的文档:
https://doris.apache.org/zh-CN/docs/admin-manual/resource-admin/workload-group#%E9%85%8D%E7%BD%AE-cpu-%E7%9A%84%E7%A1%AC%E9%99%90

1 先确认be环境是否有cgroupv1,确认路径“/sys/fs/cgroup/cpu”是否存在
2 在be.INFO中确认是否已经将查询线程写入cgroup配置,日志如下,需要注意的是这个日志只会再be启动时打印
I20240723 18:02:45.129148 1602921 cgroup_cpu_ctl.cpp:101] add thread 1602921 to group 1 success
1602921是线程号,1是workload group的id
3 去be.INFO中grep关键字“cgroup cpu_hard_limit=”,确认BE是否开启硬限模式
4 在be.INFO中确认查询是否使用了预期的group,通过关键字“use workload group”确认
如果以上均验证通过,但是依然限制不住cpu,那么可以使用top命令grep下具体的线程名称来计算group的cpu用量,因为目前workload group只限制了查询和导入的一部分逻辑的cpu,类似后台线程没有做限制,因此如果是观察进程级别的cpu使用是会大于配置的值。