详细报错信息如下:
2024-03-01 10:54:06,245 ERROR yarn.ApplicationMaster: User class threw exception: org.apache.spark.sql.catalyst.analysis.NoSuchDatabaseException: Database 'dw_srclog' not found
org.apache.spark.sql.catalyst.analysis.NoSuchDatabaseException: Database 'dw_srclog' not found
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.requireDbExists(SessionCatalog.scala:192)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.setCurrentDatabase(SessionCatalog.scala:288)
at org.apache.spark.sql.connector.catalog.CatalogManager.setCurrentNamespace(CatalogManager.scala:104)
at org.apache.spark.sql.execution.datasources.v2.SetCatalogAndNamespaceExec.$anonfun$run$2(SetCatalogAndNamespaceExec.scala:36)
at org.apache.spark.sql.execution.datasources.v2.SetCatalogAndNamespaceExec.$anonfun$run$2$adapted(SetCatalogAndNamespaceExec.scala:36)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.sql.execution.datasources.v2.SetCatalogAndNamespaceExec.run(SetCatalogAndNamespaceExec.scala:36)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result$lzycompute(V2CommandExec.scala:40)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:40)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.executeCollect(V2CommandExec.scala:46)
at org.apache.spark.sql.Dataset.$anonfun$logicalPlan$1(Dataset.scala:228)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3687)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3685)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:228)
at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:99)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:96)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:618)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:613)
at com.selectdb.x2doris.DorisDataLoader$.hiveToDoris(DorisDataLoader.scala:198)
at com.selectdb.x2doris.DorisDataLoader$.main(DorisDataLoader.scala:65)
at com.selectdb.x2doris.DorisDataLoader.main(DorisDataLoader.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:732)
2024-03-01 10:54:06,267 INFO yarn.ApplicationMaster: Final app status: FAILED, exitCode: 15, (reason: User class threw exception: org.apache.spark.sql.catalyst.analysis.NoSuchDatabaseException: Database 'dw_srclog' not found
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.requireDbExists(SessionCatalog.scala:192)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.setCurrentDatabase(SessionCatalog.scala:288)
at org.apache.spark.sql.connector.catalog.CatalogManager.setCurrentNamespace(CatalogManager.scala:104)
at org.apache.spark.sql.execution.datasources.v2.SetCatalogAndNamespaceExec.$anonfun$run$2(SetCatalogAndNamespaceExec.scala:36)
at org.apache.spark.sql.execution.datasources.v2.SetCatalogAndNamespaceExec.$anonfun$run$2$adapted(SetCatalogAndNamespaceExec.scala:36)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.sql.execution.datasources.v2.SetCatalogAndNamespaceExec.run(SetCatalogAndNamespaceExec.scala:36)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result$lzycompute(V2CommandExec.scala:40)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:40)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.executeCollect(V2CommandExec.scala:46)
at org.apache.spark.sql.Dataset.$anonfun$logicalPlan$1(Dataset.scala:228)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3687)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3685)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:228)
at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:99)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:96)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:618)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:613)
at com.selectdb.x2doris.DorisDataLoader$.hiveToDoris(DorisDataLoader.scala:198)
at com.selectdb.x2doris.DorisDataLoader$.main(DorisDataLoader.scala:65)
at com.selectdb.x2doris.DorisDataLoader.main(DorisDataLoader.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:732)
)
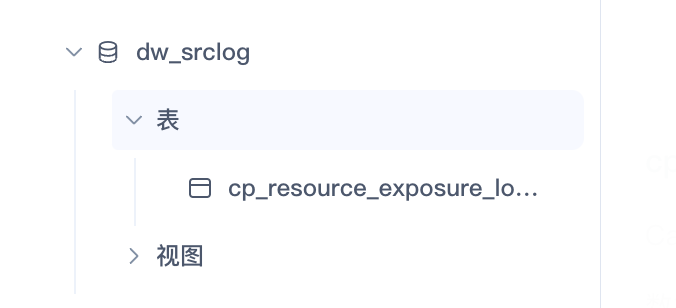
确认我们的 hive/spark 集群都是没有问题,且自建spark作业提交能正常读取到 hive 数据
X2Doris 版本是selectdb-x2doris-1.0.1