一、业务背景
1.存在问题
①数据采集性能差
②数据变更能力差
③数据分析性能差
④离线任务跑批时间长
⑤运维成本高
⑥集群稳定性差
⑦各部门口径不统一
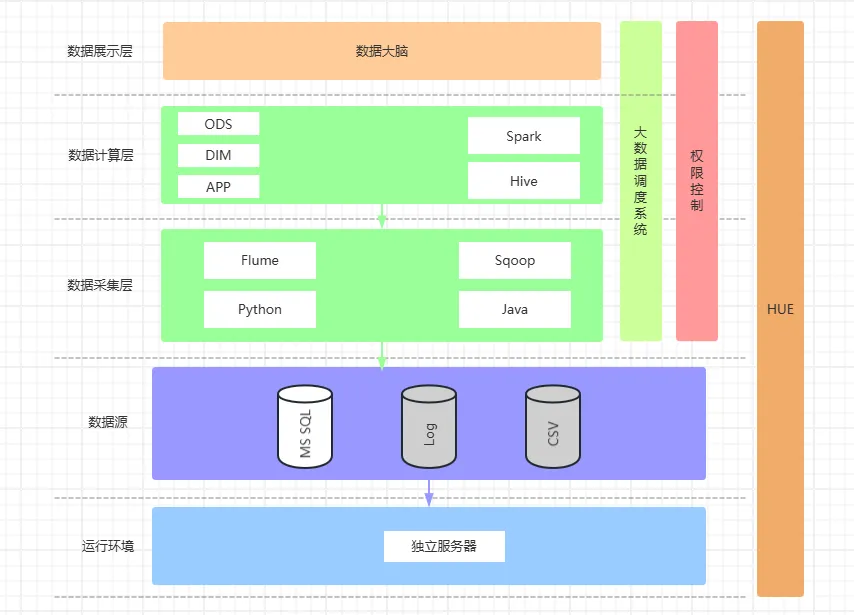
2.现有架构
二、性能优化
1.合理使用表模型
ods使用主键模型,使用Datax根据gmt_modify增量更新数据的方式替代全量覆盖,利用了主键模型的replace特性;
dwd、app使用明细模型并合理选取排序键;
dws使用聚合模型配合bitmap实现高效聚合,降低SQL复杂度。
2.基础--分区分桶
设置动态分区,事实表中一般选取时间列为分区键粒度根据数据量大小来,分区下设分桶,分桶大小按照3-5G结合自身集群规模来决定。
3.前缀索引
在Doris中,前缀索引是一种稀疏索引。表中按照相应的行数的数据构成一个逻辑数据块 (Data Block)。每个逻辑数据块在前缀索引表中存储一个索引项,索引项的长度不超过 36 字节,其内容为数据块中第一行数据的排序列组成的前缀,在查找前缀索引表时可以帮助确定该行数据所在逻辑数据块的起始行号。由于前缀索引比较小,所以,可以全量在内存缓存,快速定位数据块,大大提升了查询效率。比如在指定日期或者区域范围内的查询,可加速查询性能。一般将where后的常用字段设计到前缀索引中,不建议出现String类型,会截断。
4.日志全文检索性能优化
在检索上,Doris支持简单的等值与范围查询加速,也支持文本字段(中英文)的全文检索、多关键词检索(MATCH_ANY、MATCH_ALL)、短语检索、slop、多字段检索,相较LIKE模糊匹配性能有很大的改善。
二、问题解决
1.单Query异常导致某Be服务下线
2.0版本中我们在压测过程中发现,where条件数量超过80时,会导致查询报错并且其中一台Be下线。后经排查我们分析原因在于边界场景下造成的OOM。我们在调整线程栈空间大小的基础上,限制了where条件的数量,也对全表扫描、笛卡尔积做了强限制。
2.夜间大批量离线跑批时经常有任务超时
在我们基于Doris的新架构中优化完成后,将所有运营侧任务在dolphinscheduler中上线并分配定时时间。第二天我们发现有大量任务执行失败告警信息。报错信息如下:
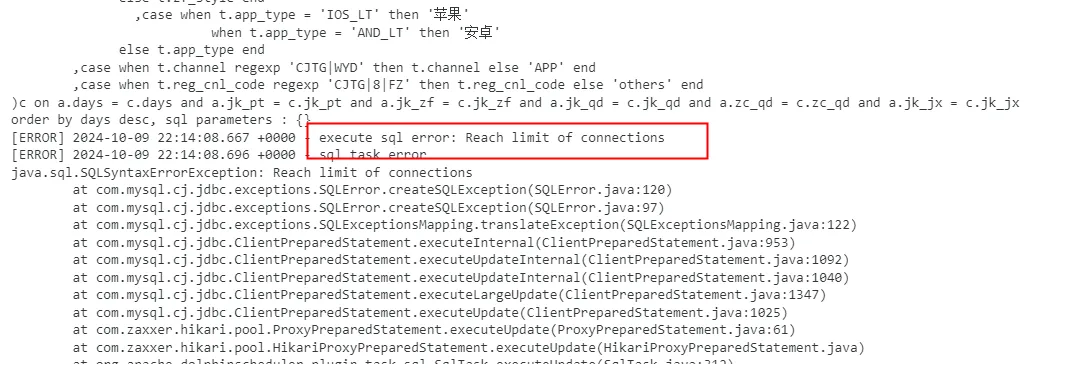
在此情况下,我们转变思路优化了工作流以及各任务配置。优化完后第二天没有出现该情况,同时我们也要对各任务的执行时长进行定期盘查(此动作完全可以代码兼容),及时优化任务(因业务数据量是一定会不断上升的)。同时我们也做了兜底操作,将 max_user_connections从默认100调大至200。
三、取得成果
1.人员开发效率提高3倍;
2.计算效率提升7-30倍;
3.数据安全性提升,同时存储率下降300%。
【1024】浙江霖梓 Doris+Flink全线数仓+日志存储一体化
Viewed 8
