测试现象
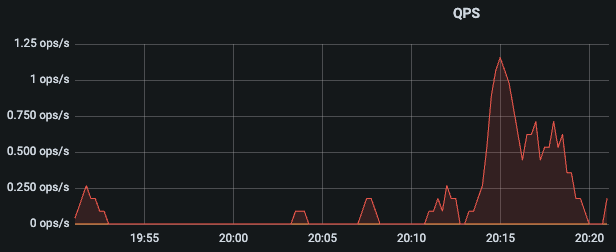
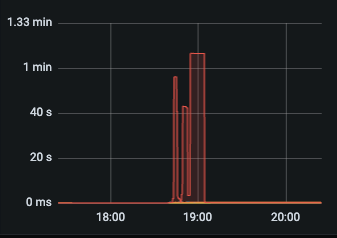
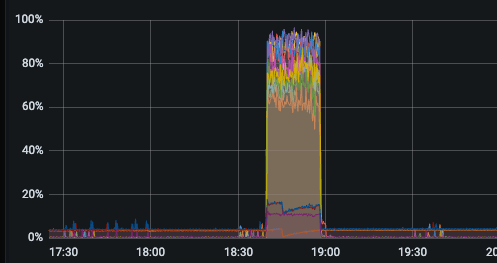
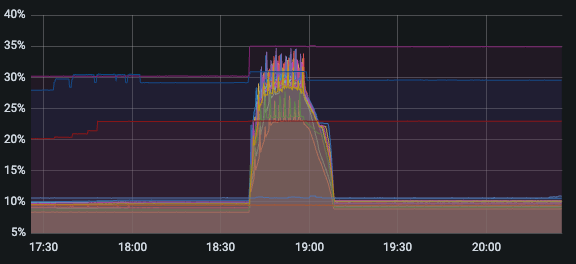
flink实时进行点查,cpu负载很高,内存使用低,io使用也不高,qps 最高只有1000多?
如何能够降低 cpu 的使用,提高内存使用,提高qps呢?
机器配置
| doris | 配置 |
|---|---|
| 3台FE | 都是16核,32G,1块系统云盘100G |
| 2台Observer | 都是16核,32G,1块系统云盘100G |
| 10台BE | 都是16核,64G,1块系统云盘100G,1块ssd数据盘1000G |
测试场景:
流程
使用flink消费kafka数据,再消费途中查询doris表,最后写入doris表
数据源读取
kafka拉取。每秒10w条
doris表情况
3副本3TB数据,unique key类型,分10个桶。
建表参数
"bloom_filter_columns"="key1,key2",
"replication_num" = "3",
"compression"="zstd",
"enable_unique_key_merge_on_write" = "true",
"light_schema_change" = "true",
"store_row_column" = "true"
查询方式
连接查询使用PreparedStatement,useServerPrepStmts=true
因业务场景问题只能使用单key1进行高并发点查
写入方式
DorisSink SteamLoad
性能情况
QPS
查询延迟
cpu负载
内存使用情况
IO情况


