我部署了一套集群环境,一个fe,三个be,使用stream load的方式将本地的csv文件导入导doris,文件每个大小74M,包含50w条记录,总共有5000个文件。刚开始导入速度很快,可达到10秒内导入一个文件,后面越来越慢,可能要几分钟才导入完成一个文件,是怎么回事?
be结点导入时的负载情况

导入日志
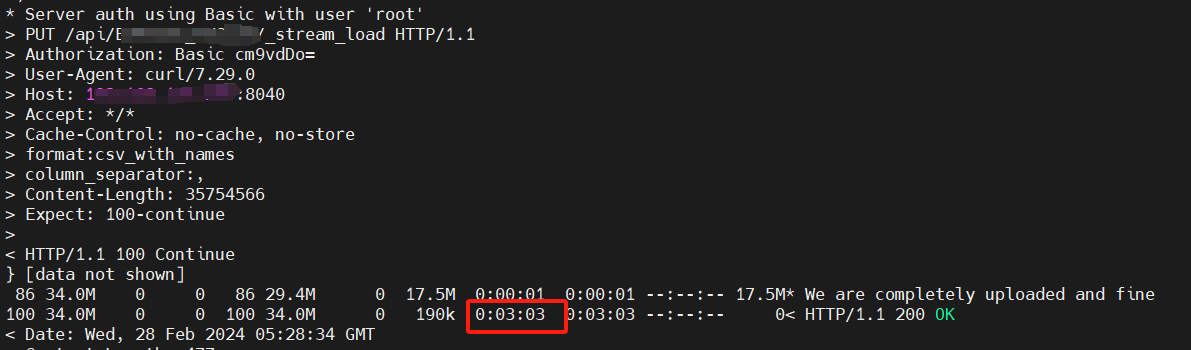
导入脚本
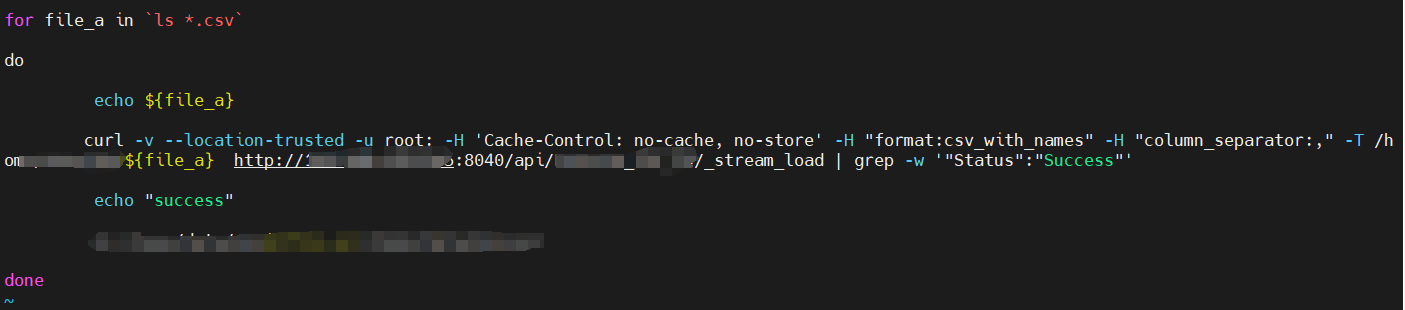
我部署了一套集群环境,一个fe,三个be,使用stream load的方式将本地的csv文件导入导doris,文件每个大小74M,包含50w条记录,总共有5000个文件。刚开始导入速度很快,可达到10秒内导入一个文件,后面越来越慢,可能要几分钟才导入完成一个文件,是怎么回事?
转发评论区,辛苦 lz 看看:
这里重启是指的重启 be 所在的机器吗?be 机器有没有监控呀?看一下 CPU、内存、磁盘 IO 瓶颈。
tablet exceeds max version num limit”的日志,这个就表示某些 tablet 的导入频率比较高,待合并的 version 比较多。如果是这样的话,解决办法,是在你的 for 循环每次循环导入之后,sleep 3-5 秒左右

