集群规模是3个fe(32c48g)+3个be(32c64g)
插入语句:
insert into tableA
select XX,XX
FROM tableB b
left join tableC c on b.id=c.id
left join tableD d on b.id=d.id
left join tableE e on d.id=e.id
where b.create_time > '2024-04-10'
语句类似是这样,表都是千万级别,大概执行需要30秒
查询语句:
select * from A_table a left join B_table b on a.id=b.id,该查询语句在正常的时候是0.2秒-1秒之间波动
如果此刻在插入,查询耗时就会去到6 7秒甚至10多秒,插入的表与查询的表不是同一批,互相独立
如果不是执行insert 只是select,比如执行
select XX,XX
FROM tableB b
left join tableC c on b.id=c.id
left join tableD d on b.id=d.id
left join tableE e on d.id=e.id
where b.create_time > '2024-04-10'
对查询语句的影响就比较小,通常2 3秒内就能出结果,请问该如何进行优化?
----------------追加----------------
后来我按照官方文档尝试了WORKLOAD GROUP资源隔离,没有起到什么作用;
也尝试了Resource Group,把3个BE的tag其中一个设置为etl,用户只能使用etl的资源,并且把表属性都设置了一遍,数据均衡结束后观察,效果并不理想,感觉资源还是没有隔离开,使用etl用户在批次任务跑的期间,其他的查询性能还是很低,是否doris就不适合用来跑批次任务,只适合用来查询?
设置如下:
表

BE
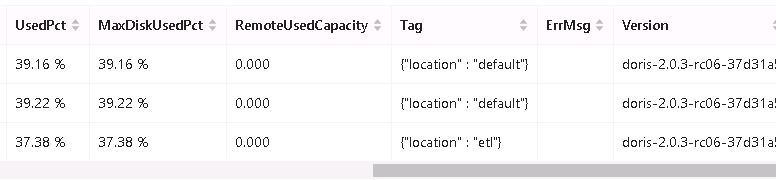
用户

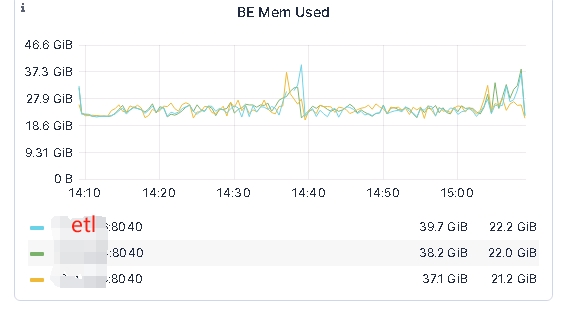
执行期间BE内存表现,etl所在be,内存也没有表现得比其他be高很多
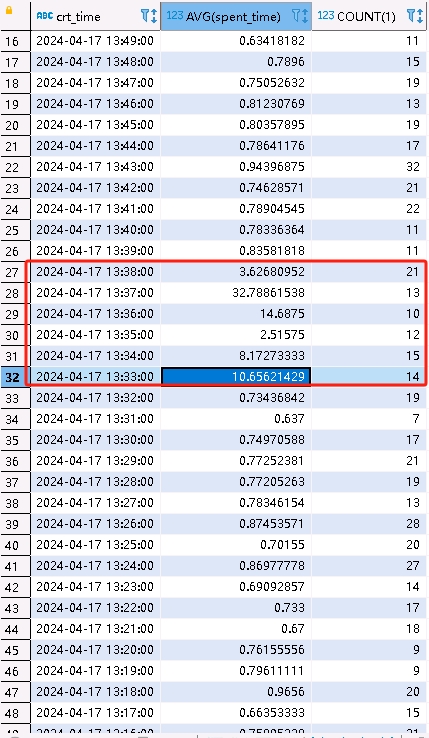
实际效果如图,同一个接口在批次任务执行期间(13:33-13:38分)表现出来的性能还是很差