环境 hive 3.1.3
doris 2.1.5
hudi 0.12
spark 3.2.2
1、spark 写入hudi 数据到hive
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "spark_hudi"
val basePath = "file:///tmp/spark_hudi"
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
.withColumn("a",split(col("partitionpath"),"\\/")(0))
.withColumn("b",split(col("partitionpath"),"\\/")(1))
.withColumn("c",split(col("partitionpath"),"\\/")(2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option("hoodie.table.name", tableName).
option("hoodie.datasource.hive_sync.enable","true").
option("hoodie.datasource.hive_sync.mode","hms").
option("hoodie.datasource.hive_sync.metastore.uris", "thrift://127.0.0.1:9083").
option("hoodie.datasource.hive_sync.database", "default").
option("hoodie.datasource.hive_sync.table", "spark_hudi").
option("hoodie.datasource.hive_sync.partition_fields", "").
option("hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor").
mode(Overwrite).
save(basePath)
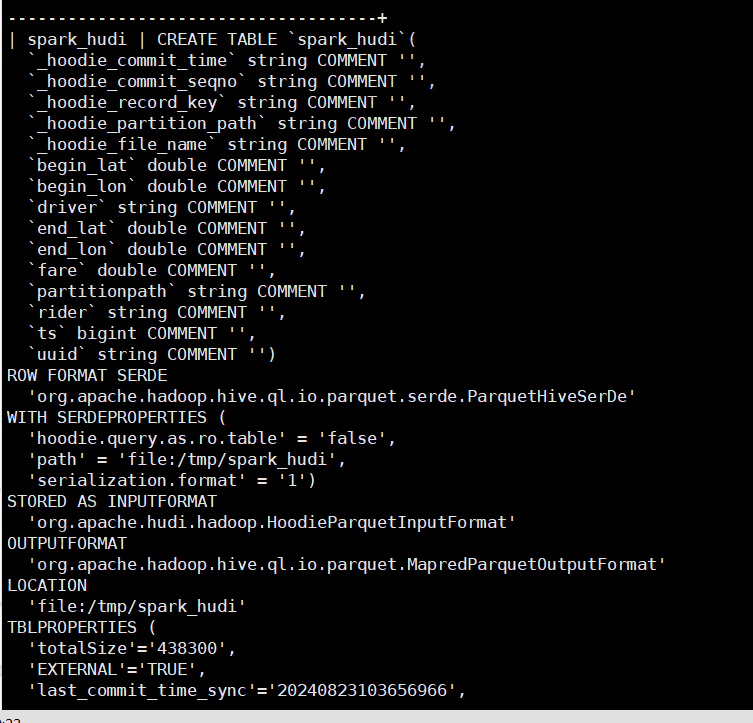
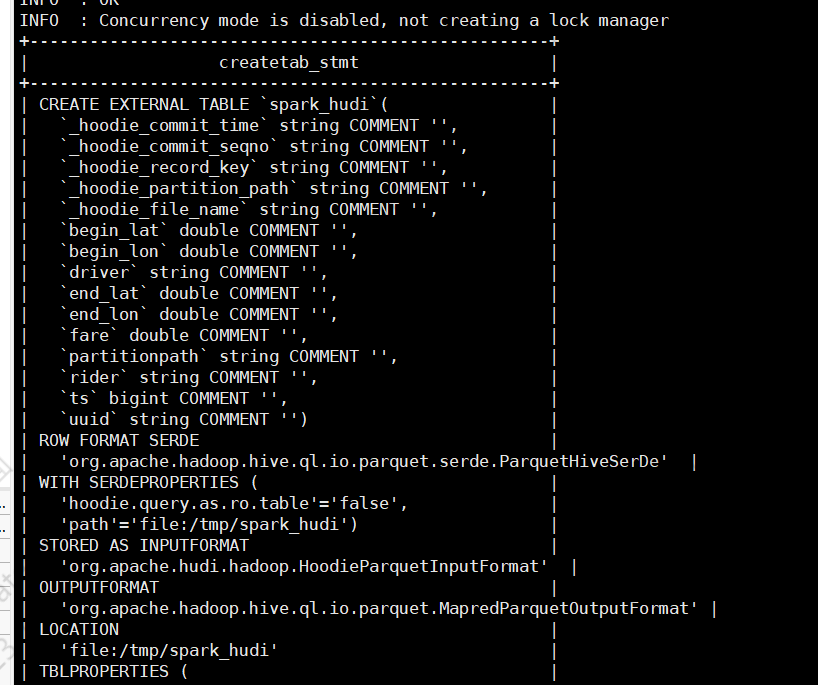
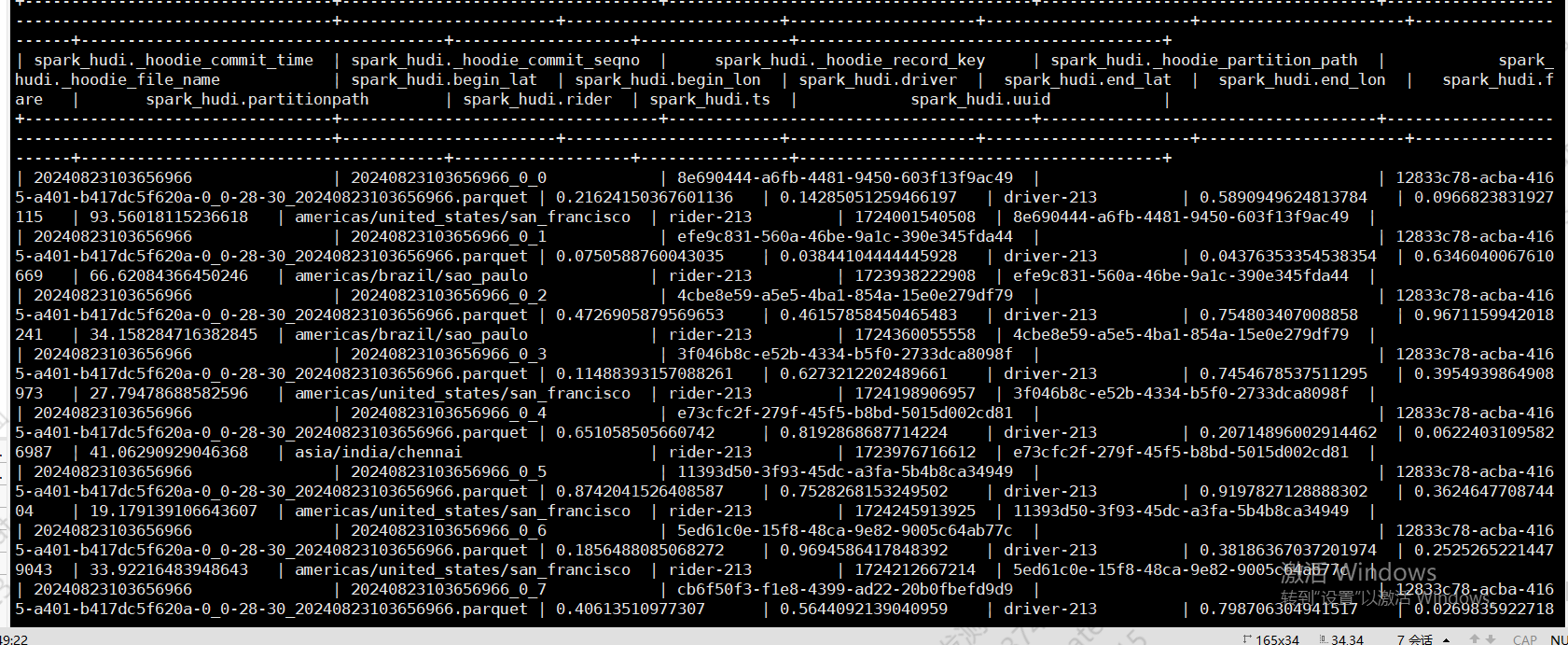
2、hive 创表语句 和查询

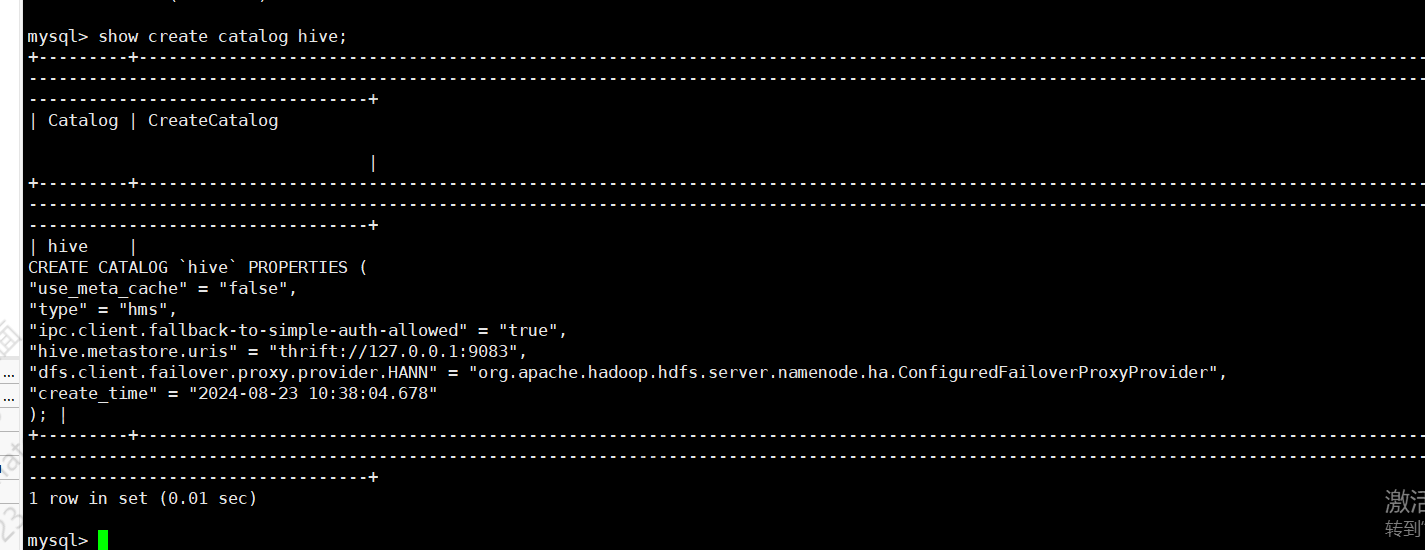
3、doris 创建catalog 和查询
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://127.0.0.1:9083',
'dfs.client.failover.proxy.provider.HANN'='org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider'
);
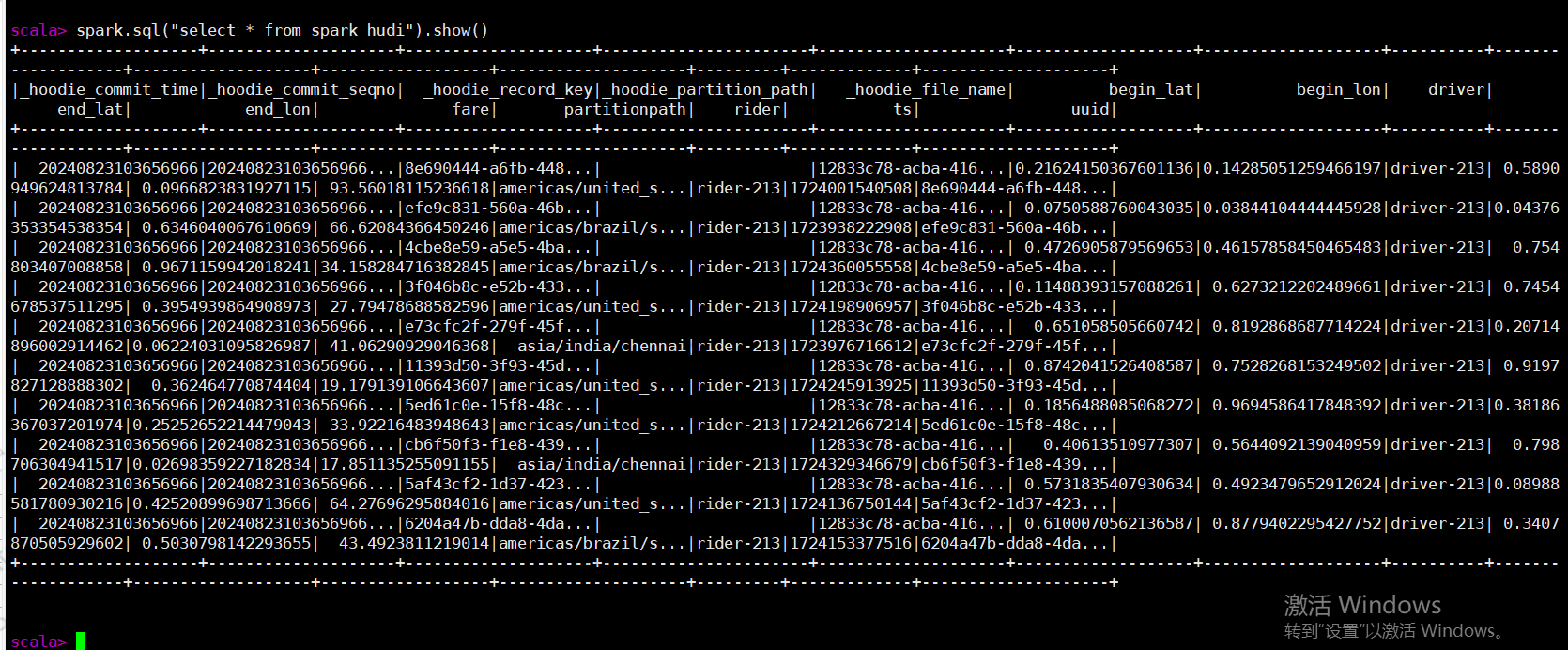
4、查询hivecatalog 数据
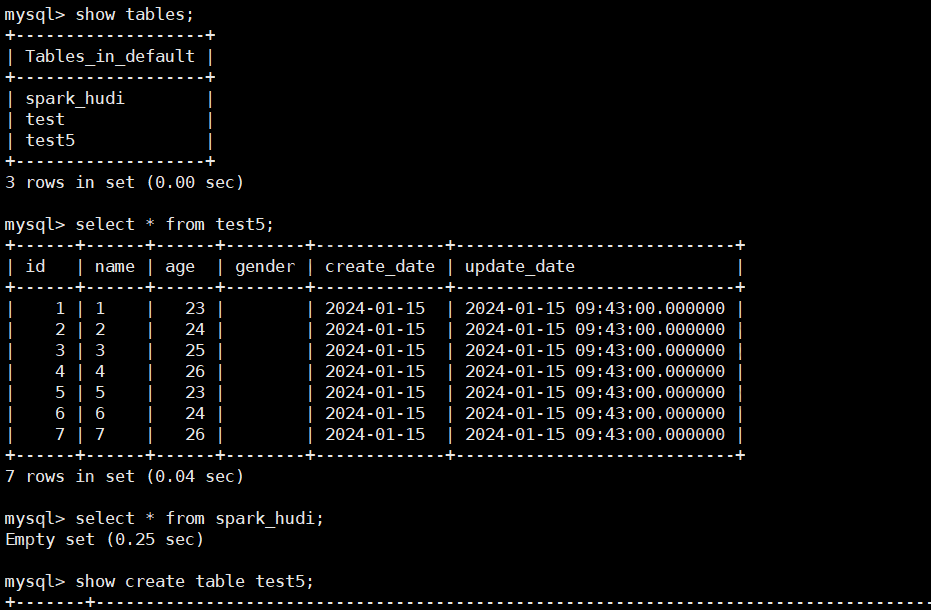
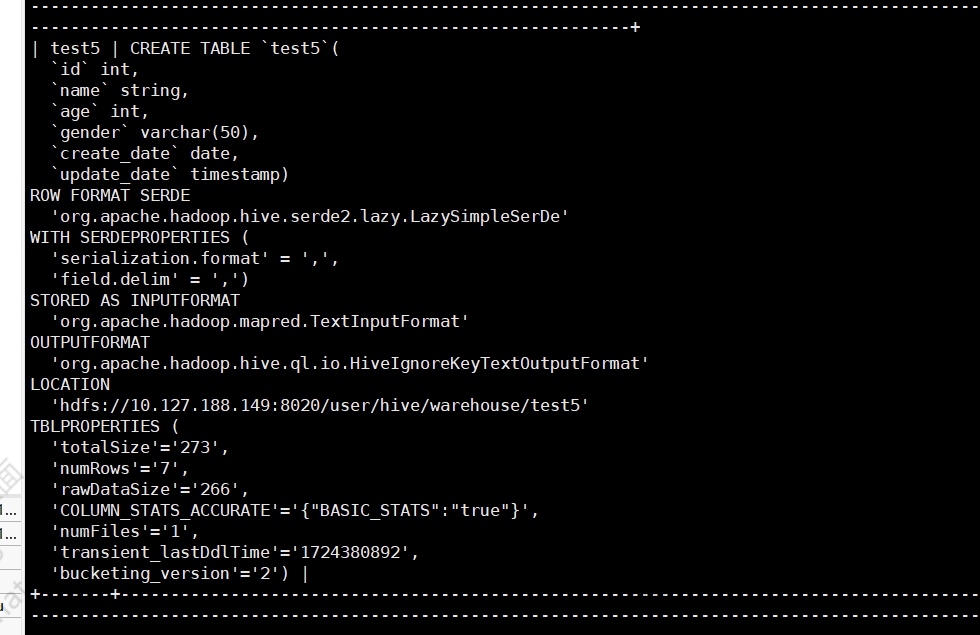
5、doris 查询 hive表的创表语句