hive建表sql
CREATE EXTERNAL TABLE `test`.`xxxx`(
`event_name` string,
`user_id` binary)
STORED AS TEXTFILE
LOCATION
's3://pupumall-dc-tmp/tmp/test1/bitmap_error/';
生成bitmap的sql
CREATE TEMPORARY FUNCTION to_bitmap AS 'org.apache.doris.udf.ToBitmapUDAF'
using jar 's3://xxxx/hive-udf_doris_bitmap.jar';
INSERT OVERWRITE TABLE `test`.`xxxx`
SELECT event_name, user_id
FROM (
SELECT
event_name, to_bitmap(hash(user_id)) AS user_id
FROM (
SELECT
event_name
FROM
dwd_user.xxxxx
GROUP BY event_name
)
GROUP BY event_name
);
查询spark sql
查询结果就一条数据,bitmap_count这个udf是我从官网的master分支编辑的jar包
create temporary function bitmap_count as 'org.apache.doris.udf.BitmapCountUDF'
USING JAR 's3://xxxx/hive-udf_doris_bitmap.jar';
select
bitmap_count(user_id)
from `test`.`xxxx`
where event_name = 'aaa'
查询报错异常
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 7.0 failed 4 times, most recent failure: Lost task 0.3 in stage 7.0 (TID 469) (ip-172-17-21-31.cn-north-1.compute.internal executor 10): java.lang.ArrayIndexOutOfBoundsException: 1
at org.apache.doris.common.io.Roaring64Map.getLongCardinality(Roaring64Map.java:304)
at org.apache.doris.common.io.BitmapValue.cardinality(BitmapValue.java:104)
at org.apache.doris.udf.BitmapCountUDF.evaluate(BitmapCountUDF.java:60)
at org.apache.spark.sql.hive.HiveGenericUDF.eval(hiveUDFs.scala:181)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.apply(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificUnsafeProjection.apply(Unknown Source)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:459)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:351)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:898)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:898)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
排查源码:
doris/fe/fe-common/src/main/java/org/apache/doris/common/io/Roaring64Map.java
目前只能追溯到这个ensureCumulatives方法出了问题
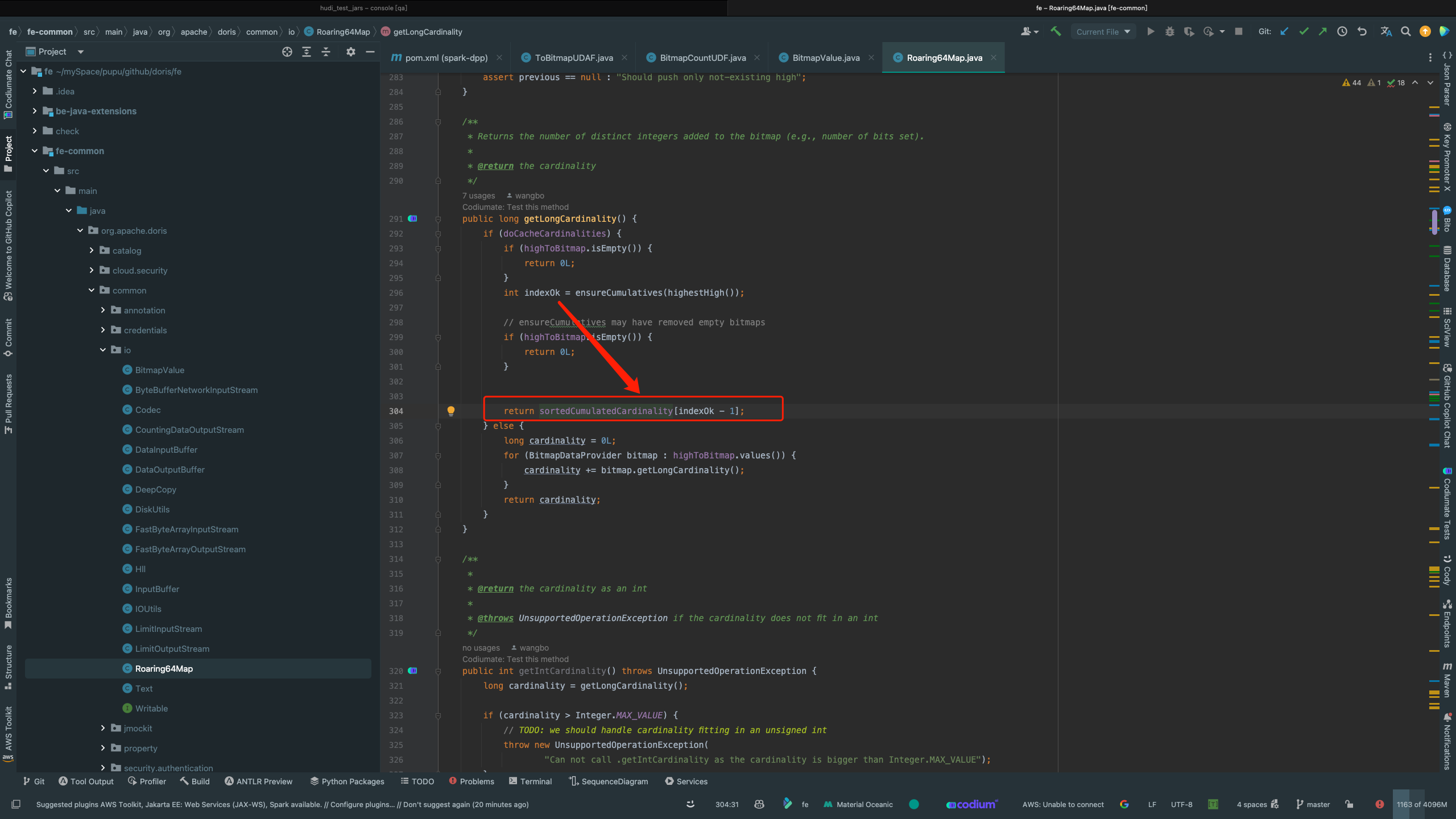
问题
想问的是我使用spark-sql生成bitmap的时候用spark的hash()函数,to_bitmap(hash(user_id))是否可以?生成bitmap是没有异常,就是读取的时候报错了。
我有从hive的路径目录下拉取一个文件,但是这边不能上传,不然还可以提供给社区直接帮忙排查

