问题描述:1.现在要对大表添加字段,除了重建表后再把原始数据insert回来,还有没有高效的其他方法?
2.SHOW ALTER TABLE COLUMN where State ='RUNNING';
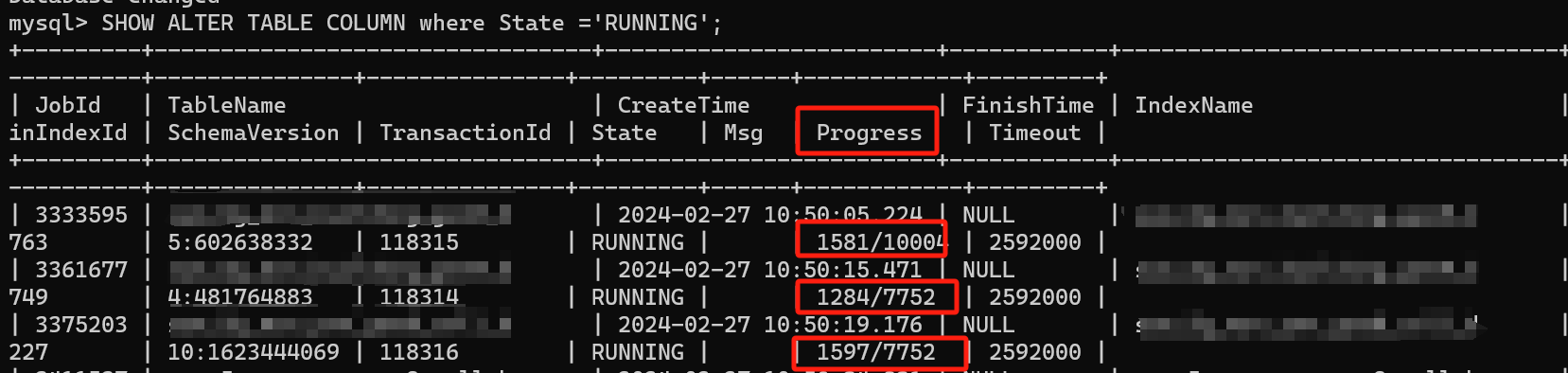
已知数据量大小有差异,其中的progress进程是大表进程数就多,有什么参数或者什么相关的计算公式吗?
问题描述:1.现在要对大表添加字段,除了重建表后再把原始数据insert回来,还有没有高效的其他方法?
2.SHOW ALTER TABLE COLUMN where State ='RUNNING';
已知数据量大小有差异,其中的progress进程是大表进程数就多,有什么参数或者什么相关的计算公式吗?
动态分区表以指定分区的bucket数为准 dynamic_partition.buckets,如果buckets = 1 的话,会导致单个tablet非常大,处理起来会更慢,建议重新建表保持合理的分桶数,并开启 light schema change
另外我这边又发现个情况,就是change期间的process中的数量=动态分区中的buckets值 * 表当前分区数量。同时为了数据分布均匀,假如我有13台服务器,每台服务器分了2个be节点,那么我如下建表是否合理?(本意是避免数据碎片化太多,减少change过中的创建的process过大。我在chage过程中,偶尔会提示 Node catalog is not ready, please wait for a while.)
1.DISTRIBUTED BY HASH(eci) BUCKETS 10 改为 DISTRIBUTED BY HASH(eci) BUCKETS 26
2."dynamic_partition.buckets" = "26" 改为 "dynamic_partition.buckets" = "1"
CREATE TABLE dev.tmp_data
(
starttime DATETIME ,
endtime DATETIME ,
eci bigint ,
scene_id varchar(100) ,
city varchar(10) ,
/*
业务字段将近200个
*/
tmp_test bigint
)
ENGINE=olap
DUPLICATE KEY(starttime, endtime, eci,scene_id)
COMMENT "9级栅格小区竞对指标_天级"
PARTITION BY RANGE(starttime)()
DISTRIBUTED BY HASH(eci) BUCKETS 26
PROPERTIES(
"dynamic_partition.enable" = "true",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.history_partition_num"="2",
"dynamic_partition.start" = "-366",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "1",
"replication_num" = "2",
"compression"="zstd"
);


