我需要导入116.7G的数据到一张空表(计划还要导入更多):

导入命令如下:
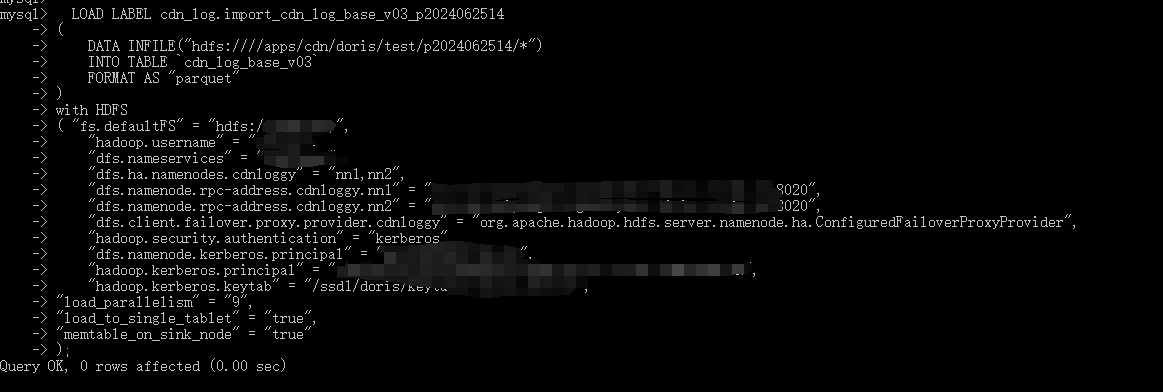
前几分钟各个be节点的cpu和内存上涨:
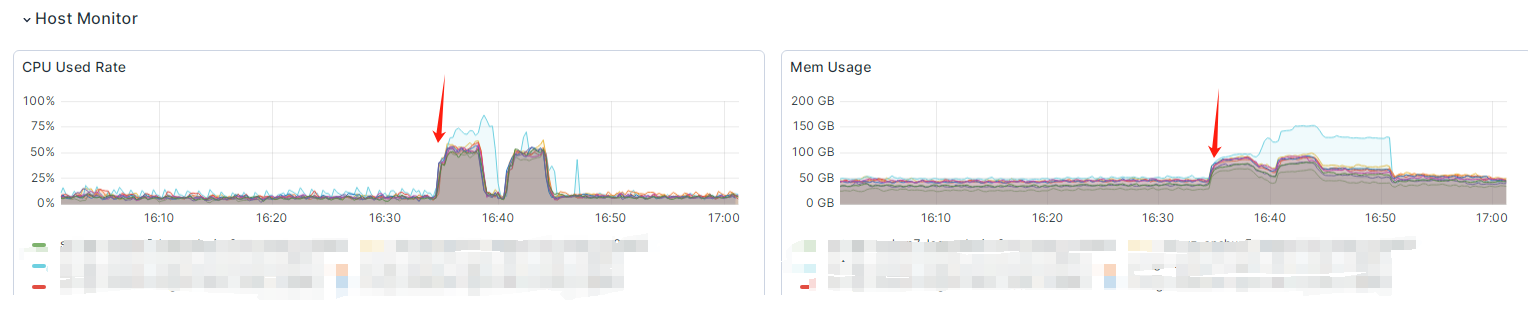
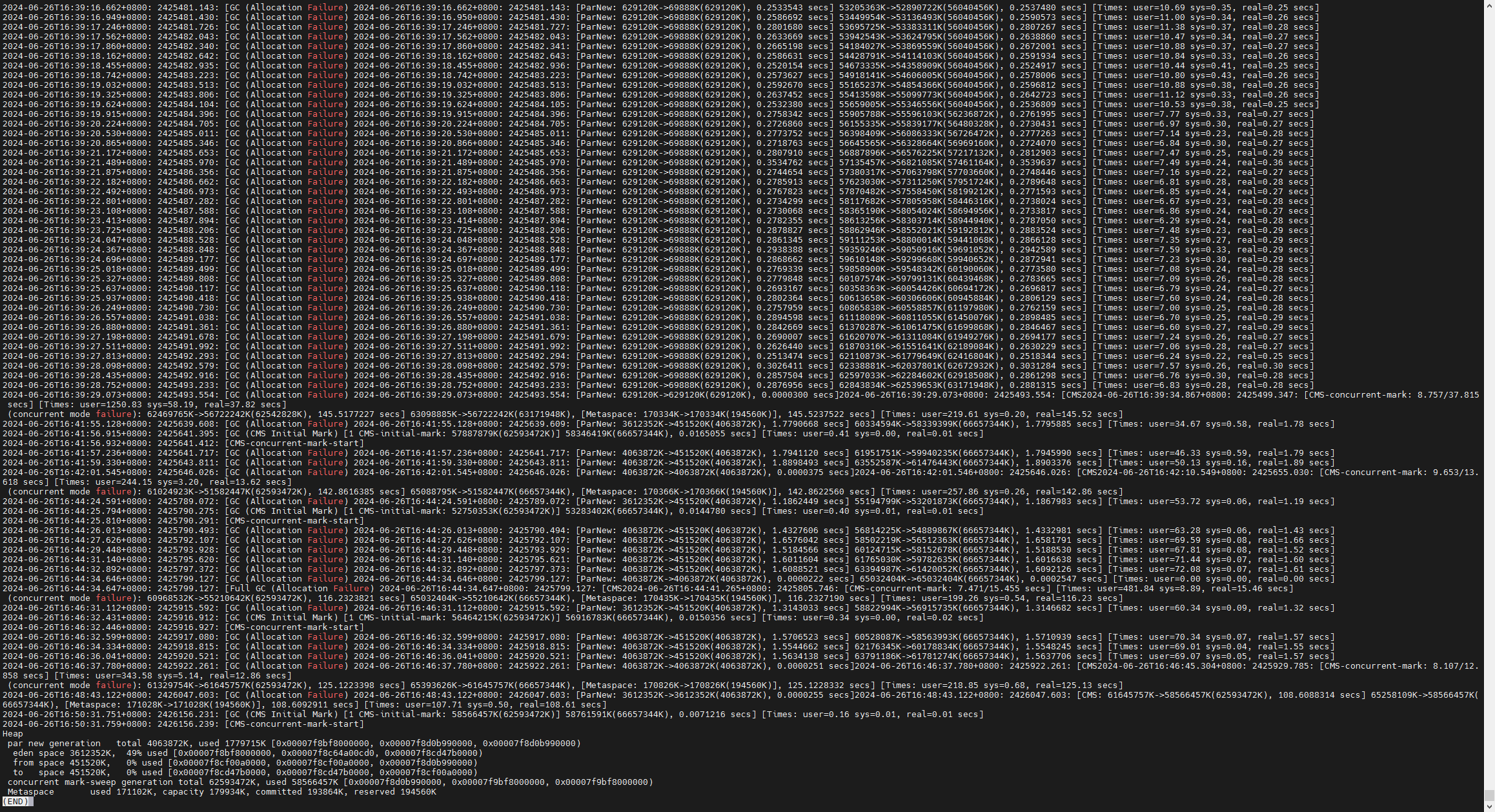
这也属于正常情况, 但是在cpu使用率下降之后, fe master的内存一直飙升, 最终挂掉, 并且长时间起不起来:
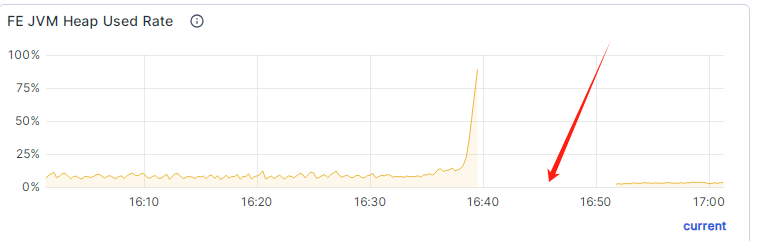
这时候查询导入任务状态会长时间卡住, Ctrl+C 取消后会打印出结果,但是进度一直没更新, 同时想取消这个导入任务失败,提示不存在该导入任务:
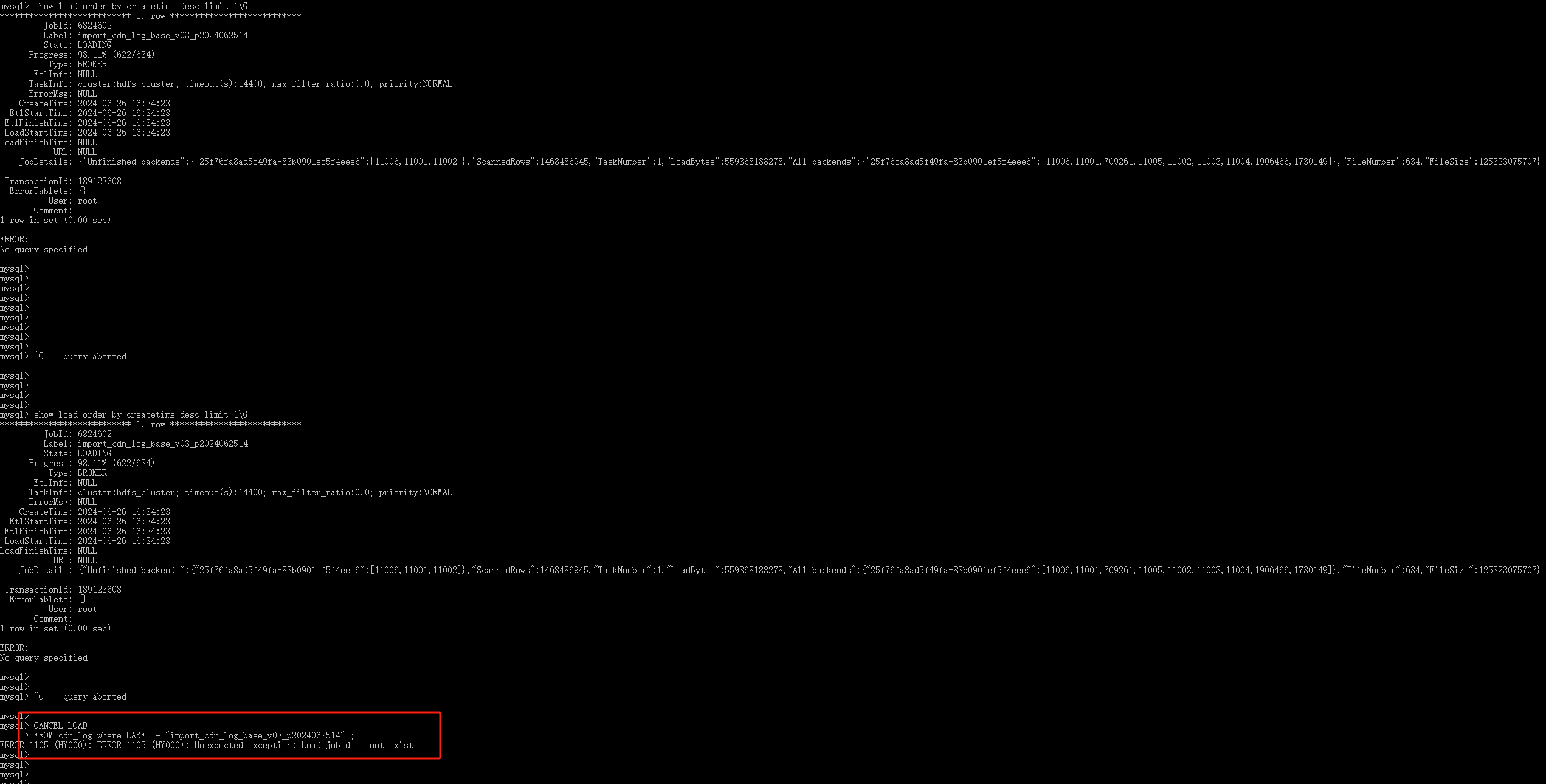
然后其他fe 相继挂掉 (但是恢复时间比第一个挂掉的时间短) :

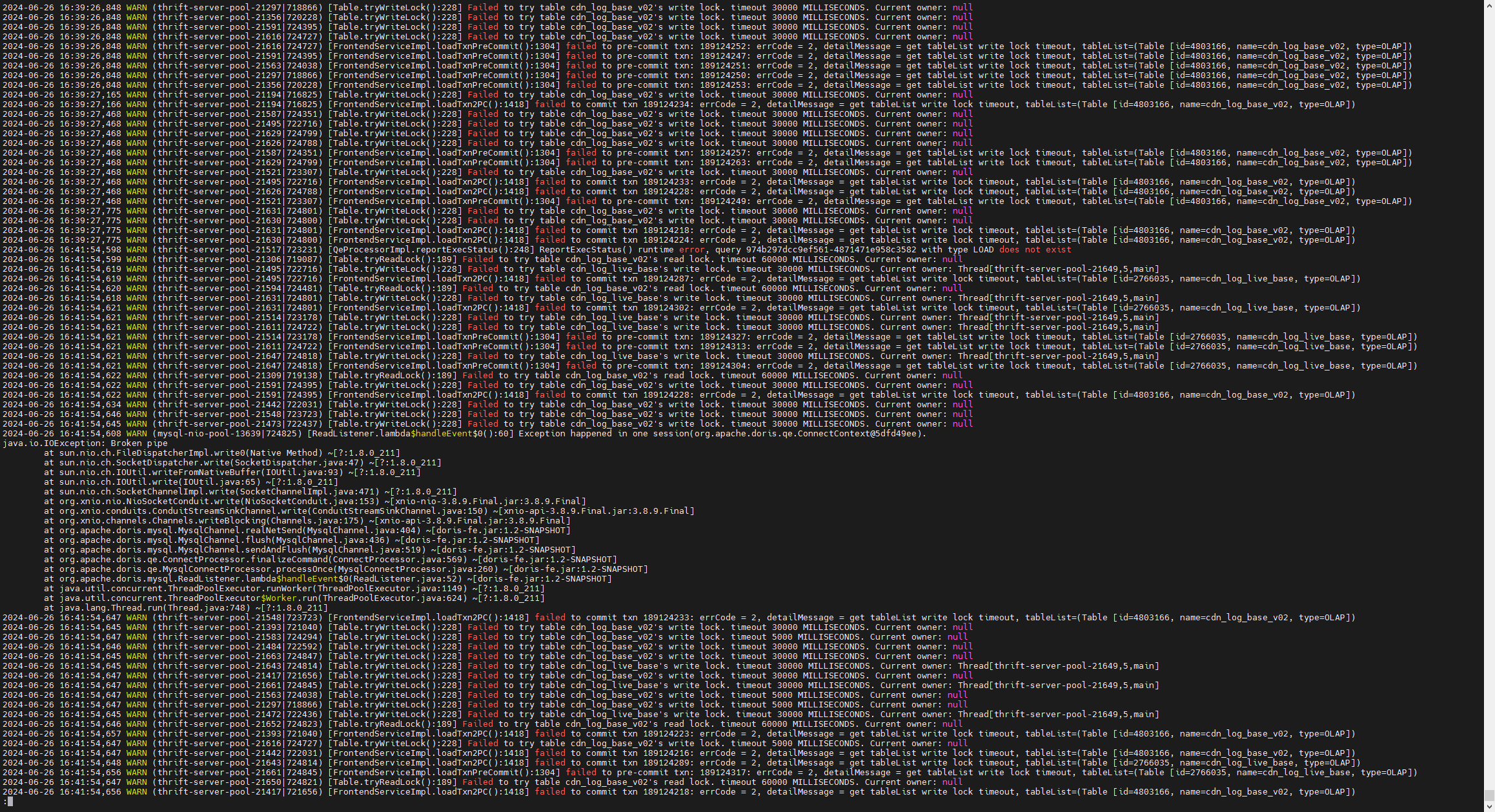
其他在实时导入的任务受到影响:
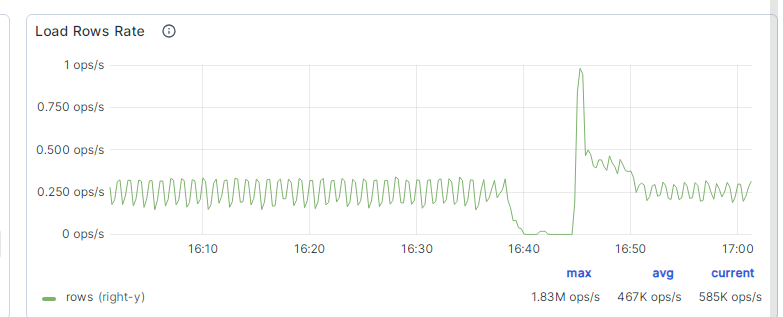
挂掉的 fe 尝试启动日志:
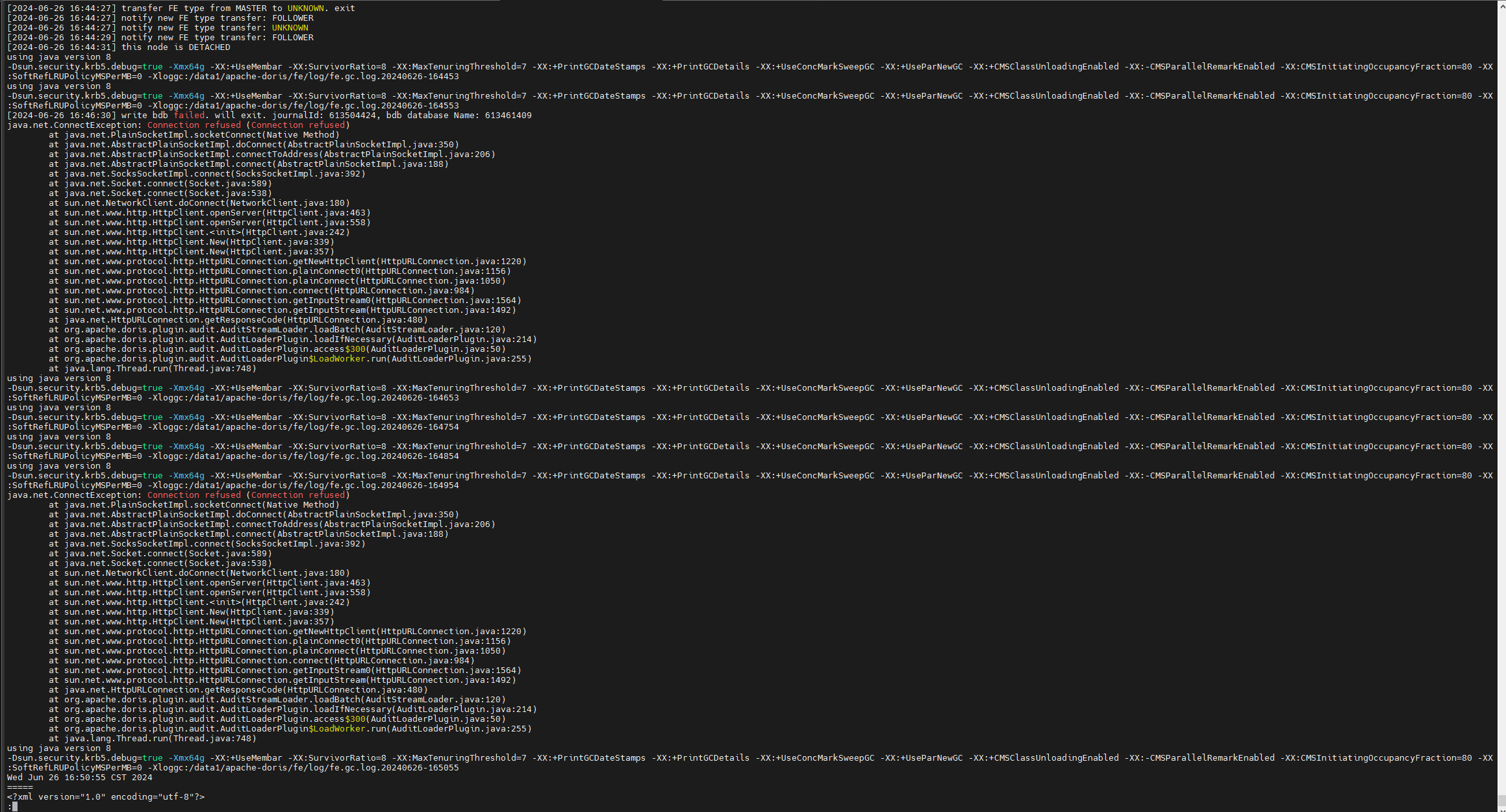
fe.warn 部分日志:
fe gc 日志:
类似问题 : 同步物化视图在存量数据比较多的情况下创建失败
请问我怎么导入才能减小或者避免对集群的影响?
是否需要其他日志进行问题查看?

